
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
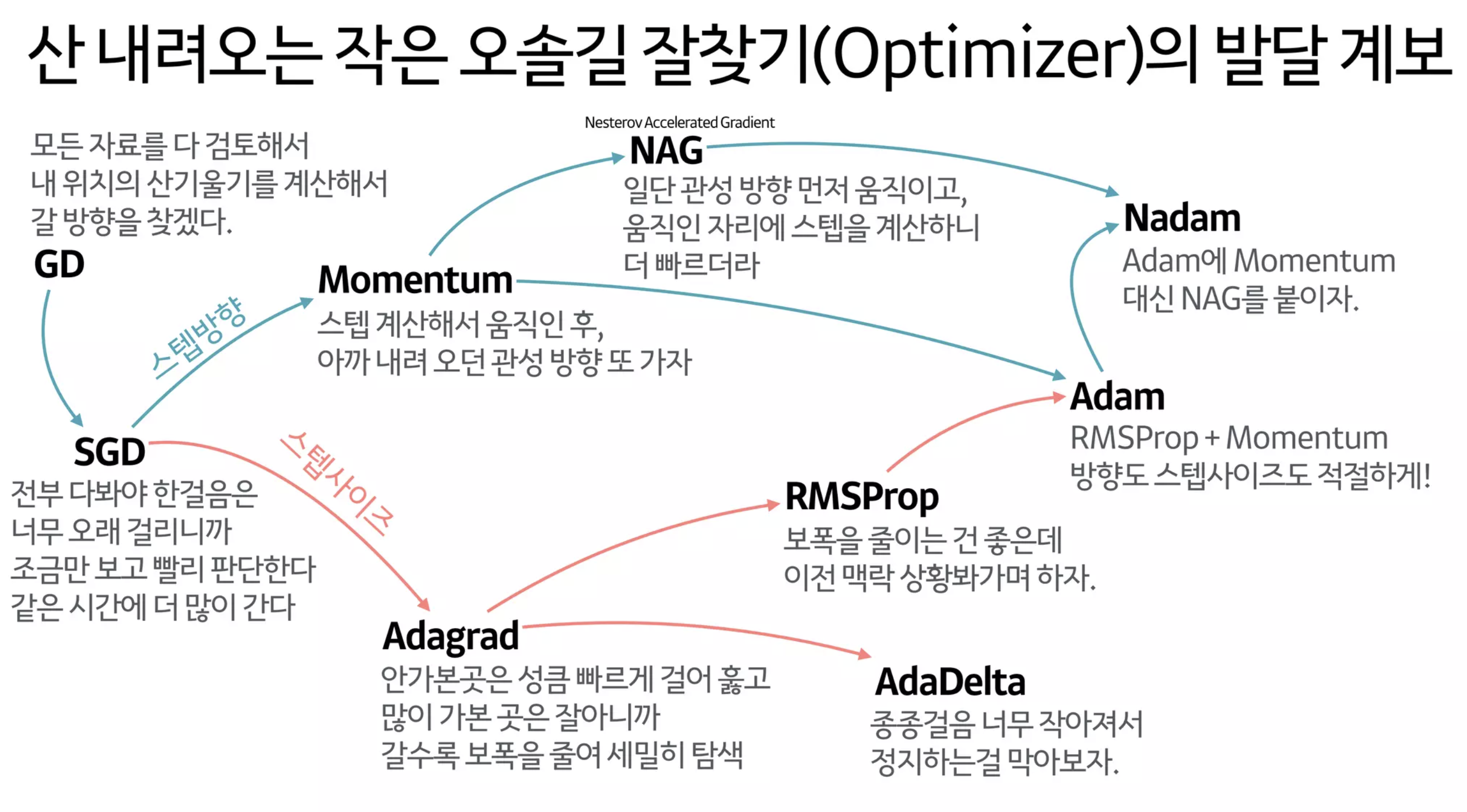
- 클래스 분류
- 개체명 인식
- 문맥을 반영한 토픽모델링
- 옵티마이저
- 데이터리안
- 포아송분포
- 피파온라인 API
- 다항분포
- Tableu
- 코사인 유사도
- KeyBert
- 붕괴 스타레일
- 자연어 모델
- 트위치
- LDA
- 블루 아카이브
- BERTopic
- 블루아카이브 토픽모델링
- 데이터넥스트레벨챌린지
- 토픽 모델링
- Optimizer
- geocoding
- NLP
- CTM
- 데벨챌
- Roberta
- 구글 스토어 리뷰
- 원신
- 조축회
- SBERT
- Today
- Total
분석하고싶은코코
모델 최적화를 위한 옵티마이저(Optimizer) 본문
오늘 포스팅할 주제는 머신러닝, 딥러닝 모델에서 필수적인 존재인 옵티마이저(Optimizer)에 대해서 이야기해보겠습니다.
옵티마이저를 한 문장으로 이야기 하자면 다음과 같습니다. '목적지까지 가는 길을 최적화 해주는 방법(알고리즘)이다.'
정말 간단한 예시로 아래와 같은 상황에서 출발지에서 맛집을 찾아가는 과정으로 예를 들어보겠습니다. 저희는 전지적 시점이기에 그냥 오른쪽으로 쭉 가면 되잖아? 라고 하지만 그렇지 않고 맛집이 존재하는 것에 대해서는 알고 있지만 맛집이 어디에 있는지는 모르는 상황에서 찾아가는 것입니다. 그렇다면 우리는 출발지에서 오른쪽만 가는게 아니라 아래쪽으로도 가보는 선택을 하고 맛집까지 도착하는 경험을 하게 됩니다. 그렇게 모든 갈 수 있는 모든 길을 탐색하고나서 '아, 출발지에서 오른쪽으로 쭉 가는게 맛집으로 가는 최적화된 경로구나!'라고 생각하게 됩니다.
| 출발지 | ? | ? | ?(맛집) |
| ? | ? | ? | ? |
실제로 이러한 가정은 우리가 데이터를 통해 데이터에 맞는 모델이 최적이 형태를 찾아가는 것과 동일한 과정입니다. 모델도 최적의 가중치를 처음부터 맞출 수 없습니다. 그렇기 때문에 훈련 데이터를 바탕으로 그 가중치를 찾아가고 그 과정에서 손실함수가 필요하고 이 손실함수를 최소화하는 방향으로 가중치를 수정해 나가는 과정이 최적화 알고리즘이 필요한 구간이 됩니다.
산 내려오는 작은 오솔길 찾기 과정을 옵티마이저에 적용한 방법은 왼쪽 상단에 있는 경사 하강법(GD)입니다. 즉 우리는 지금까지 모든 경로(자료)를 다 검토해보고 내 위치에서 어디로 가야할지 정했던 것이죠. 이 경사 하강법을 좀 더 이해하기 쉽게 표현해보자면 '경사는 미분 값이고 그 미분 값으로 (가중치를)움직여 모델을 최적화한다.'로 표현할 수 있습니다. 그런데 이 방법이 모든 데이터를 바탕으로 이뤄지다보니 너무 비효율적이니 일부만 사용해서 그 경사 하강법을 진행하자는게 확률적 경사하강법(SGD)입니다. 그런데 SGD 방법을 더 효율적으로 만들자하여 파생된 옵티마이저 알고리즘들이 있습니다. 그러면 이렇게 파생된 다양한 옵티마이저들을 알아보겠습니다.
확률적 경사 하강법(Stochastic Gradient Descent, SGD)
확률적 경사 하강법은 GD와 다르게 한번 학습할 때 모든 데이터에 대해 가중치를 조절하는 것이 아니라, 랜덤하게 추출한 일부 데이터에 대해 가중치를 조절합니다. 결과적으로 속도는 개선되었지만 항상 좋은 최적 해를 찾는다는 보장은 없습니다.
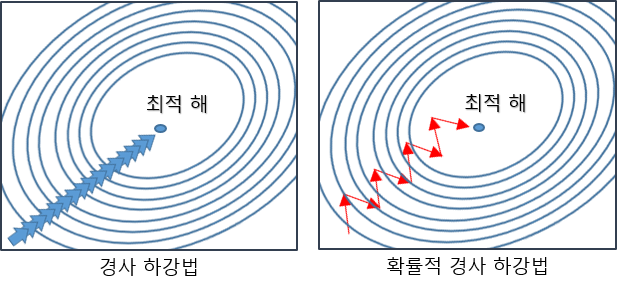
속도 개선을 위해 SGD는 전체 데이터가 아닌 일부 데이터만을 통해서 나아간다는 것이 차이점입니다. 그래서 나아가는 과정에서 사용하는 수식은 아래의 식으로 동일합니다. 알파(α)는 learning rate, Cost(w)는 비용함수로 훈련 데이터를 통해 나온 손실의 평균입니다. 이 값이 GD는 모든 데이터, SGD는 일부 데이터만을 사용해 가중치 업데이트가 이뤄지게 됩니다.

모멘텀(Momentum)
모멘텀은 관성, 탄력이라는 뜻입니다. 말 그대로 내가 가려고 하는 방향이 있지만 이전에 했던 행동으로 인해서 영향을 받는 것이죠. 즉, '이전 스텝에서 진행했던 업데이트에 대한 방향의 관성'으로 이해하시면 됩니다. 이 방향은 음의 방향과 양의 방향이 존재하게 되는데 관성으로 인해 한쪽 방향으로만 움직이면 이 또한 문제가 되니 비율을 통해서 그 정도를 정하게 되고 일정 수준이되면 반대 방향으로 바뀌게 되는 것이죠. 이를 통해서 좀더 일관성 있는 방법으로 최적 해를 찾아가는 과정이 됩니다.
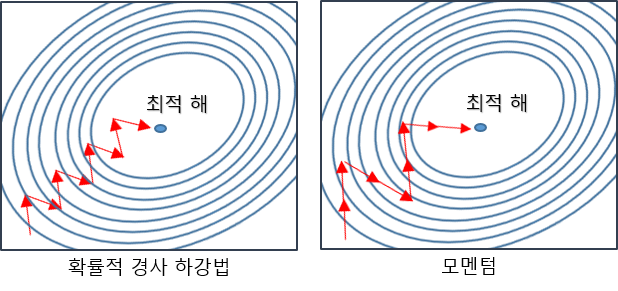
이러한 모멘텀 과정을 간단하게 예를 들어보겠습니다. 모멘텀의 수식은 아래와 같습니다. V(t)가 관성이 적용된 업데이트 할 값이 됩니다. 아래 수식의 m은 모멘텀 값으로 하이퍼파라미터가 됩니다. 이제 이 수식에 실제 값을 대입한 예를 들어보겠습니다. gradient 값이 0.5이고 두 번째 gradient 값이 -0.3이라 할 때 m이 0.9라면 V(1)은 -0.5, V(2)는 0.9 * -0.5 +0.3 = -0.45 + 0.3 = -0.15가 됩니다. 즉 방향(음->양)이 변경 되어야 하는 상황임에도 이전 업데이트에 대한 관성으로 그 방향이 틀어지지 않고 나아가는 정도가 달라지게 되는 것입니다.

네스테로브 모멘텀(Nesterov Accelrated Gradient, NAG)
NAG는 모멘텀에서 조금 더 효율적인 방법으로 파생된 알고리즘입니다. 조금 복잡해보이지만 그림을 통해서 이해하면 쉽습니다. 아래와 같이 모멘텀은 그라디언트와 모멘텀 두 가지를 따로 계산하여, 두 값을 바탕으로 최종 값을 찾았습니다. 그런데 이 과정에서 좀 더 효율적인 방법으로 제시된 것이 모멘텀을 구하고 그 자리에서 그라디언트를 구하자라는 접근법입니다. 그러면 하나의 과정이 사라지고 좀 더 효율적이다라는 방법이었던 것이죠.

수식을 통해 확인해 볼 수 있습니다. 업데이트를 하기 위한 값을 구하는 과정에서 현재 그라디언트 값의 계산 과정에서 모멘텀 값이 사용되는 것을 볼 수 있습니다.

Adagrad
앞서 이야기한 모멘텀의 경우 방향에 초점을 맞춘 파생 알고리즘들입니다. 그런데 지금부터 이야기할 Adagrad, RMSporp의 경우에는 방향이 아닌 경험(?)에 초점을 맞춘 방법입니다. 지금 저희가 다루고 있는 최적화 알고리즘은 SGD에서 파생된 알고리즘들입니다. 그렇기 때문에 업데이트 과정에서 사용된 데이터가 있고 아닌 데이터가 있게 됩니다. 이 부분에서 새로운 접근법을 적용한 것이죠. '업데이트 된 가중치들은 좀 더 최적 해에 가까운 값들로 변경됐을 것'이라는 가정이 있는 알고리즘입니다. 즉, 학습을 통해서 최적 해에 가까워 지고 있으니 이후 학습에서 너무 많은 변화를 주면 좋지 않다는 것입니다.
Adagrad는 같은 입력 데이터가 여러번 학습되는 학습모델에 유용합니다. 대표적으로는 자언어와 관련된 Word2Vec이나 GloVe입니다. 학습 단어의 등장 확률에 따라 변수의 사용 비율이 확연하게 차이나기 때문에 많이 등장한 단어는 가중치를 적게 수정하고 적게 등장한 단어는 많이 수정할 수 있기 때문입니다.
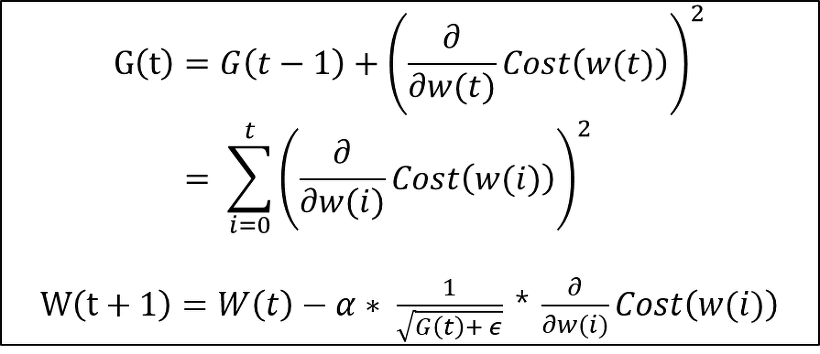
식을 보면 지금까지 변화했던 과정들에 대한 값G(t)를 구합니다. W(t+1)을 업데이트하는 식을보면 G(t)값을 지금의 그라디언트 값과 lr를 곱하여 업데이트를 하는 것을 볼 수 있습니다. 그런데 여기서 문제점이 G(t)값이 너무 커지면 업데이트 값이 0에 수렴하여 움직이지 않는 상황이 발생해 버립니다. 이를 해결하고자 등장한 것이 RMSprop입니다.
RMSprop
RMSprop는 Adagrad에 지수 이동 평균을 적용하자라는 접근법입니다. 지수 이동평균에 대한 이해를 위해 간단한 예를 들어보자면 시계열 데이터가 대표적입니다. 이에 대한 값으로 주식, 비트코인에 대한 값을 생각해보죠. 외부세력에 대한 간섭이 없다고 가정했을때 값에 대한 변화가 과연 30일전에 값에 영향을 많이 받을까요 아니면 어제의 값에 영향을 많이 받을까요? 당연히 오늘의 값은 어제에 값에 더 큰 영향을 받겠죠? 이를 통해 오늘의 값을 예측한다고 했을때 가중치를 알파(α)라고 했을때 (1-α)의 n승으로 그 영향을 낮출 수 있게 된다는 것이죠.
이 방법을 Adagard의 이전 학습에서 최근 학습에 조금더 가중치를 주어 G(t)값을 구하면 가중치가 업데이트되는 과정에서 0이 발생하는 것을 막을 수 있다는 방법론이 됩니다. 여기서 지수 이동평균에 대한 가중치는 감마로 표현되었습니다.

아담(Adaptive Moment Estimation, Adam)
아담은 앞서 알아봤던 방향에 대한 접근법과 학습 경험에 대한 접근법 두 가지를 융합한 알고리즘입니다. 그래서 그런지 많은 논문들에서 사용한 옵티마이저를 보면 아담 혹은 아담 베이스의 변형 옵티마이저들이 많이 사용되는 것을 확인할 수 있었습니다. 그렇다고 이 아담이 항상 최고의 옵타마이저라고는 할 수 없습니다. 여튼 이 아담의 접근은 반반 옵티마이저로 모멘텀과 RMSprop 두 가지를 결합한 옵티마이저라는 것입니다.

그런데 업데이트를 위한 값W(t+1)을 찾을때 단순하게 두 알고리즘에서 값을 구해 결합한 M(t), V(t)를 사용하지 않습니다. ^(hat)을 씌운 보정 값을 사용하게 됩니다. 그 이유는 M_0, V_0모두 0의 값을 갖는데 이를 그대로 사용하게 되면 0에 수렴하는 현상이 나타날 수 있습니다. 이를 방지하고자 보정값을 사용하게 되고 이 값은 초기에 0으로 수렴하지 않게 하기 위한 장치이고 최종적으로는 크게 영향을 주지 않는 것으로 초기의 문제점을 해결하고 결과에는 큰 영향을 주지 않는 결과를 만들어 낼 수 있게 됩니다.
α(lr)=0.001, β1로는 0.9, β2로는 0.999, ϵ 으로는 10^-8 값이 가장 좋은 Default값이라고 논문에 명시되어 있습니다.
결론(?)
옵티마이저의 근본적인 접근법인 GD이외에도 Newton's-Method(뉴턴 법)같은게 존재합니다. 오늘 포스팅에서 다룬 옵티마이저들은 모두 SGD의 파생으로 first-order optimization에 속합니다. 그런데 뉴턴 법의 경우 second-order optimization에 속합니다. 1차와 2차의 차이는 몇번째 도함수로 미분을 몇번 시행하는가?라는 뜻입니다. 이는 수렴 속도와 계산량의 trade-off관계를 갖고 있습니다. 그럼에도 SGD파생 옵타마이저들이 주류로 잡은 이유는 trade-off관계에 있어 압도적인 계산량 증가가 있기 때문입니다.
모든 모델, 데이터에 가장 잘 맞는 옵티마이저는 없다고 합니다. 왜냐하면 모든 모델도 각각의 특색을 갖고 있고 그에 사용하는 데이터 역시 사용자들에 따라 다르게 형성되어 있습니다. 심지어 같은 데이터를 사용한다고 하더라도 모델에 넣기위한 전처리를 어떻게 했느냐에 따라서도 결과가 달라지듯이 그 입력값 자체가 다릅니다. 그렇기에 옵티마이저 역시 가장 잘 맞는 옵티마이저가 무엇인지에 대해서는 사용자가 직접 판단하거나 혹은 여러 옵티마이저를 사용해 최적의 옵티마이저와 그에 맞는 하이퍼파라미터들을 찾는것이 필요합니다. 그럼에도 최근 논문들이나 다양한 모델들의 소개를 보면 기본적인 SGD혹은 Adam, 변형 Adam이 많이 사용되는게 눈이 보이긴합니다.
Reference
https://www.slideshare.net/yongho/ss-79607172
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다.
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다. - Download as a PDF or view online for free
www.slideshare.net
https://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
Gradient Descent Optimization Algorithms 정리
Neural network의 weight을 조절하는 과정에는 보통 ‘Gradient Descent’ 라는 방법을 사용한다. 이는 네트워크의 parameter들을 $\theta$라고 했을 때, 네트워크에서 내놓는 결과값과 실제 결과값 사이의 차이
shuuki4.github.io
'머신러닝&딥러닝' 카테고리의 다른 글
| 로컬 서버에 LLM 올리기 - Docker, Flask, LLM (0) | 2024.04.10 |
|---|---|
| CNN으로 온라인 게임 어뷰저 탐지해보기 (1) | 2024.02.25 |
| YOLOv8 object tracking(detecting) (0) | 2024.02.06 |
| QLoRA-Efficient Finetuning of Quantized LLMs (1) | 2024.01.24 |
| Pytorch - Error 정리 페이지 (0) | 2024.01.18 |



