
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Optimizer
- 옵티마이저
- 붕괴 스타레일
- 자연어 모델
- SBERT
- 블루 아카이브
- 블루아카이브 토픽모델링
- 구글 스토어 리뷰
- Roberta
- 포아송분포
- 원신
- 조축회
- KeyBert
- geocoding
- 코사인 유사도
- 데이터리안
- Tableu
- NLP
- 데이터넥스트레벨챌린지
- 개체명 인식
- CTM
- 데벨챌
- 토픽 모델링
- LDA
- 다항분포
- 문맥을 반영한 토픽모델링
- 트위치
- BERTopic
- 피파온라인 API
- 클래스 분류
- Today
- Total
분석하고싶은코코
따릉이 수요량 예측 본문
Dacon - 따릉이 수요량 예측
https://dacon.io/competitions/official/236029/overview/description
2022 UOS 빅데이터 알고리즘 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
이번 데이터 분석은 이전에 진행했던 따릉이 수요 예측과 다른 점은 단순히 일별 수요량만 있을 뿐 나머지 데이터가 제공되지 않았다.
데이터 분석 - 코드
기본 데이터 불러오기 및 확인
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import random
import holidays
import set_matplotlib_hangul #matplotlib 한글 설정 커스텀 py 파일
import warnings
warnings.filterwarnings(action='ignore')
%matplotlib inline
train_raw = pd.read_csv('./따릉이 수요량 예측/train.csv')
submission = pd.read_csv('./따릉이 수요량 예측/sample_submission.csv')
train_raw.head()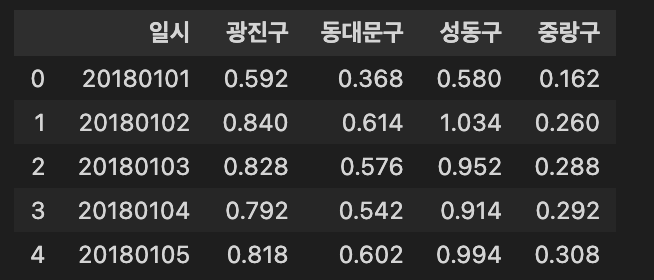
train_raw.info()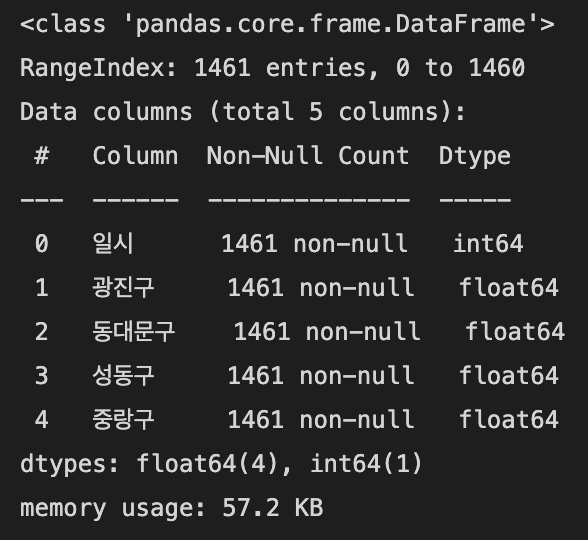
EDA
전처리
# 일시 컬럼 dtype : object -> datetime
train_raw['일시']= train_raw['일시'].astype('str')
train_raw['일시']= pd.to_datetime(train_raw['일시'])
#구별로 데이터 분할
df_광진구 = train_raw.drop(['동대문구','성동구','중랑구'],axis=1)
df_동대문구 = train_raw.drop(['광진구','성동구','중랑구'],axis=1)
df_성동구 = train_raw.drop(['광진구','동대문구','중랑구'],axis=1)
df_중랑구 = train_raw.drop(['광진구','동대문구','성동구'],axis=1)
df_list = [df_광진구, df_동대문구, df_성동구, df_중랑구]
# 년, 월, 요일 분리하여 컬럼 생성
for df_gu in df_list:
y_list = []
m_list = []
d_list = []
wd_list = []
for idx, row in df_gu.iterrows():
y_list.append(row['일시'].year)
m_list.append(row['일시'].month)
d_list.append(row['일시'].day)
wd_list.append(row['일시'].weekday())
df_gu['년'] = y_list
df_gu['월'] = m_list
df_gu['요일'] = wd_list
# df_gu.drop(['일시'], axis=1, inplace=True)
# 이후 Prophet 모델 사용을 위한 컬럼명 변경
df_광진구.rename(columns={'광진구' : 'y', '일시' : 'ds'}, inplace=True)
df_동대문구.rename(columns={'동대문구' : 'y','일시' : 'ds' },inplace=True)
df_성동구.rename(columns={'성동구' : 'y','일시' : 'ds' },inplace=True)
df_중랑구.rename(columns={'중랑구' : 'y', '일시' : 'ds'},inplace=True)
# 통합 DataFrame만들기 위해 구분을 위한 지역구 컬럼 추가
df_광진구['지역구'] = '광진구'
df_동대문구['지역구'] = '동대문구'
df_성동구['지역구'] = '성동구'
df_중랑구['지역구'] = '중랑구'
# 통합 DataFrame
df = pd.concat([df_광진구,df_동대문구,df_성동구,df_중랑구])
# 일시로 정렬
df.sort_values('일시')
# 년, 월로 그룹 정렬. 값은 이상값들이 크게 존재하는 월이 있어 평균이 아닌 중앙값 사용.
df_month_median = df.pivot_table(index=['년','월'], columns=['지역구'], values=['y'], aggfunc=np.median)
df_month_median
수요량 주말/평일 산점도
weekend = df_광진구[(df_광진구['요일'] == 5) | (df_광진구['요일'] == 6)]
weekily = df_광진구[(df_광진구['요일'] != 5) | (df_광진구['요일'] != 6)]
for df_gu in df_list:
tmp = []
for idx, rows in df_gu.iterrows():
if (rows['요일'] == 5) or (rows['요일'] == 6):
tmp.append('주말')
else:
tmp.append('평일')
df_gu['주말'] = tmp
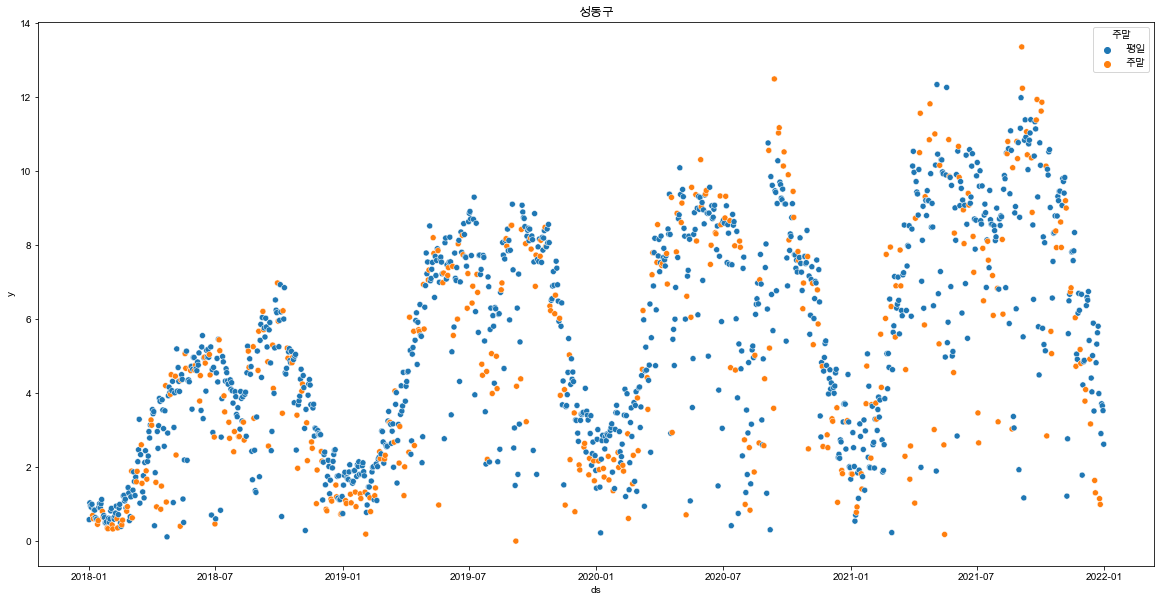
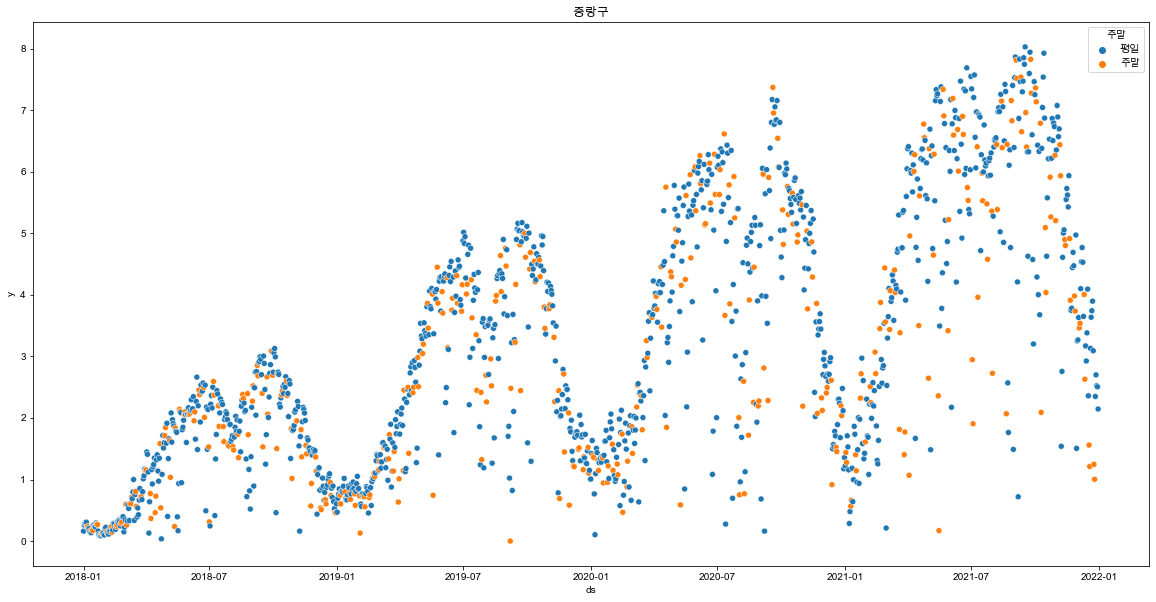
for df_gu in df_list:
plt.figure(figsize=(20,10))
sns.scatterplot(data = df_gu, x='ds', y='y', hue="주말")
plt.show()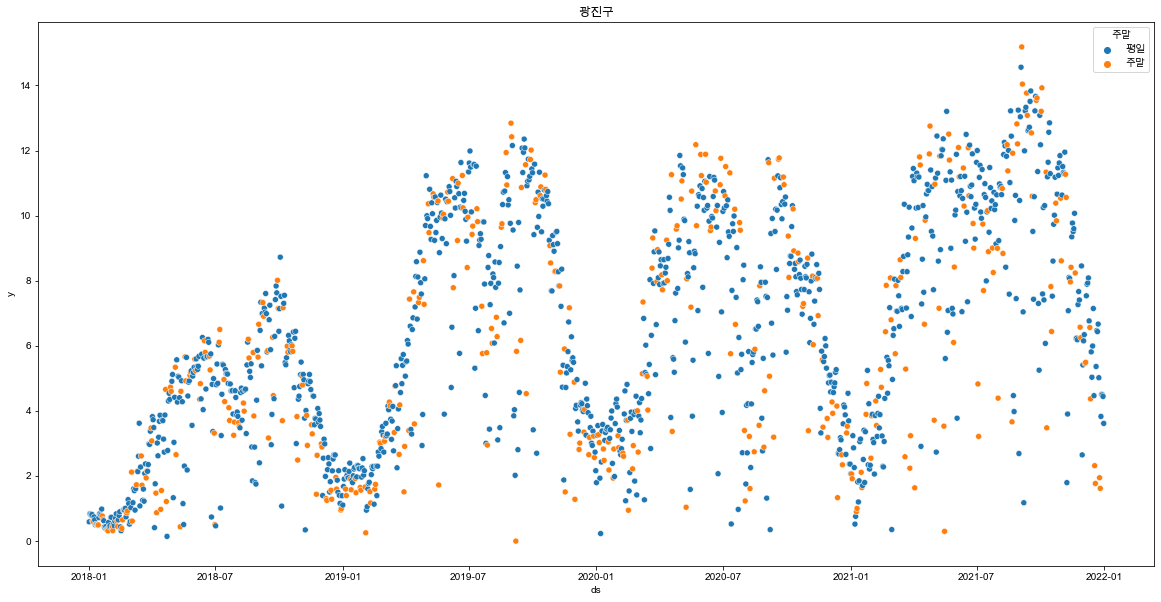

df_weekday = df.pivot_table(index=['년', '주말'], columns=['지역구'], values=['y'], aggfunc=np.mean)
df_weekday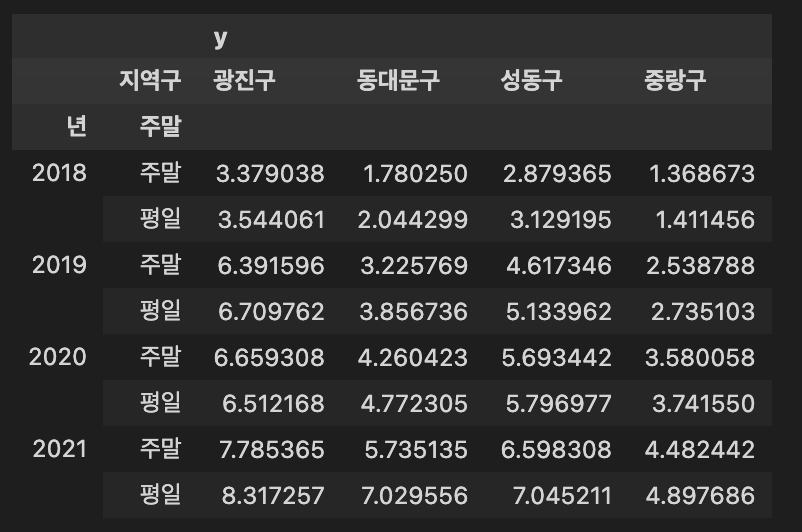
- 주말과 평일에는 어느정도 차이가 있음을 확인함.
- 모든 지역구의 산점도에서 반복되며 상승하는 진폭을 보여주어 계절성이 보임.
- 모든 년도 봄~가을 구간에 상승하는 데이터를 보여줌.
- 상승 중간 급격하게 하락하는 이상치 데이터가 존재하는데 아마 기상과 관련된 데이터일 가능성이 높아보임.
- 이번 데이터에서는 기상에 관한 정보 외부 데이터 사용이 어려우므로 일단은 그냥 진행하기로함.
Prophet 모델
시게열 데이터 분석을 위한 Prophet 모델 사용
- 바닐라 Prophet으로 선 확인.
- 이후 하이퍼 파라미터 수정하여 모델 최적화 진행
- 데이터 점점 증가하는 진동운동을 보이고 있으므로 'seasonaility_mode' 값은 'multiplicative' 값 사용
- 공휴일에 대한 데이터는 holiday에서 제공되는 기본 정보만을 사용
from fbprophet import Prophet
train_광진구 = df_광진구[df_광진구['ds']<'20210101']
true_광진구 = df_광진구[df_광진구['ds']>='20210101']
m = Prophet()
m.fit(train_광진구)
future = m.make_future_dataframe(periods=365) # 2021년 데이터 예측
forecast_광진구 = m.predict(future)
m.plot(forecast_광진구);
m.plot_components(forecast_광진구);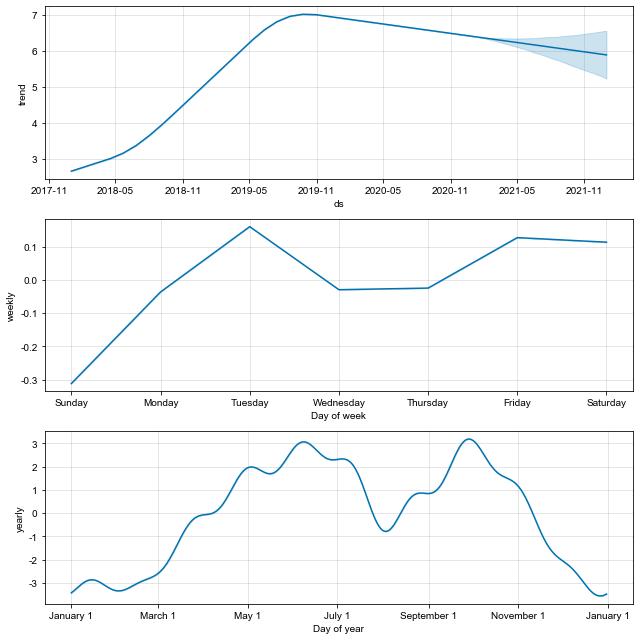
plt.figure(figsize=(20,10))
plt.plot(df_광진구['ds'],df_광진구['y'], label='True Data')
plt.plot(forecast_광진구['ds'], forecast_광진구['yhat'], label='forecast')
plt.grid()
plt.legend()
plt.show()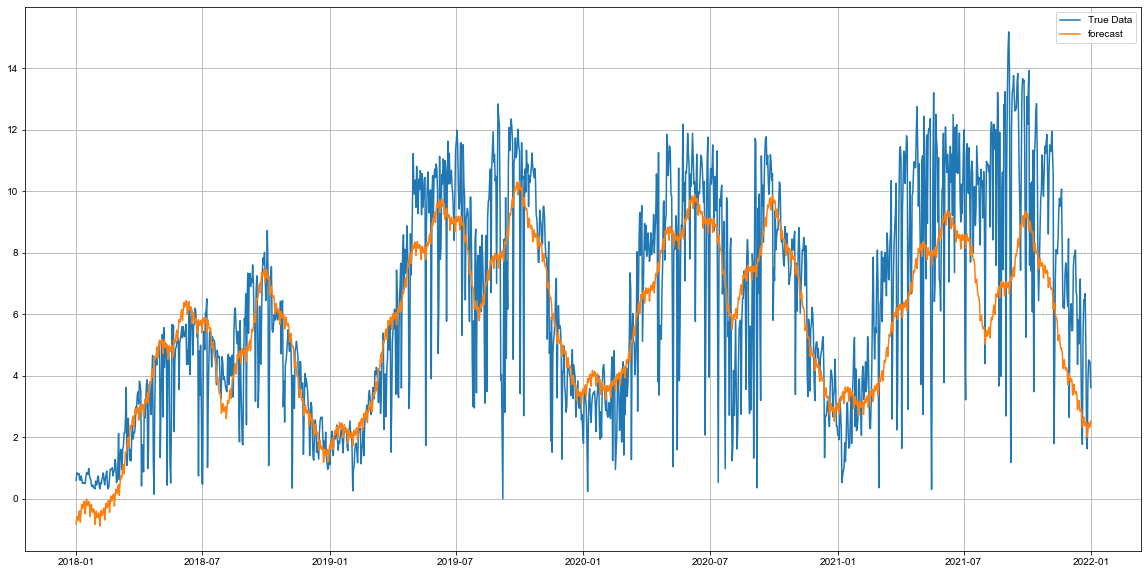
- 처음에는 얼추 비슷한 흐름으로 예측이 되어가고 있지만 2021년 이후 예측력이 완전 망가짐
- 또한 바닐라 모델에서는 트렌드의 흐름을 하락하는 흐름으로 잘못 예측하고 있음.
- 따라서 하이퍼 파라미터 튜닝을 통해서 최적값을 찾아 적용이 필요함.
하이퍼 파라미터 튜닝
최적의 파라미터를 찾을 요소들은
- changepoint_prior_scale : 트렌드를 제대로 찾기 못했기 때문에 유연하게 대처하기 위함. (너무 높게 설정하면 오버피팅의 위험성이 있음)
- 계절성 : yearly_seasonaility, seasonaility_prior_scale(연 계절성, 계절성 반영강도) 두 가지 속성으로 찾기로 함.
- holidays_prior_scale : 휴일에 대한 반영 강도. 기본적으로 제공해주는 휴일들에 대해서 얼마나 유연하게 대응할지에 대한 파라미터.
from sklearn.model_selection import ParameterGrid
params_grid = {
'changepoint_prior_scale' : [0.1, 0.2, 0.3, 0.4, 0.5],
'seasonaility_prior_scale' : [5, 10, 12, 15],
'yearly_seasonality' : [5,10,12,15],
'holidays_prior_scale' : [5, 10, 12, 15]
}
grid = ParameterGrid(params_grid)
# 최적 모델 찾기 함수화
def getBestParams(df):
isBest = 999
train_df = df[df['ds']<'20210101']
true_df = df[df['ds']>='20210101']
for p in grid:
train_model = Prophet(changepoint_prior_scale=p['changepoint_prior_scale'],
seasonality_mode = 'multiplicative',
seasonality_prior_scale = p['seasonaility_prior_scale'],
daily_seasonality=True,
yearly_seasonality=p['yearly_seasonality'],
interval_width=0.9,
holidays=holidays_df,
holidays_prior_scale= p['holidays_prior_scale']
)
train_model.fit(train_df)
train_future = train_model.make_future_dataframe(periods=365, freq='D',include_history=False)
train_forecast = train_model.predict(train_future)
MAE = mean_absolute_error(true_df['y'], train_forecast['yhat'])
if MAE < isBest:
isBest = MAE
best_model = p
return isBest, best_model
best_mae_광진구, best_params_광진구 = getBestParams(df_광진구)
best_mae_동대문구, best_params_동대문구 = getBestParams(df_동대문구)
best_mae_성동구, best_params_성동구 = getBestParams(df_성동구)
best_mae_중랑구, best_params_중랑구 = getBestParams(df_중랑구)결과
best_mae_광진구, best_mae_동대문구, best_mae_성동구, best_mae_중랑구
print('광진구 Best Params : ', best_model)
print('동대문구 Best Params : ', best_params_동대문구)
print('성동구 Best Params : ', best_params_성동구)
print('중랑구 Best Params : ', best_params_중랑구)
하이퍼 파라미터 튜닝 후 모델 재확인 (광진구)
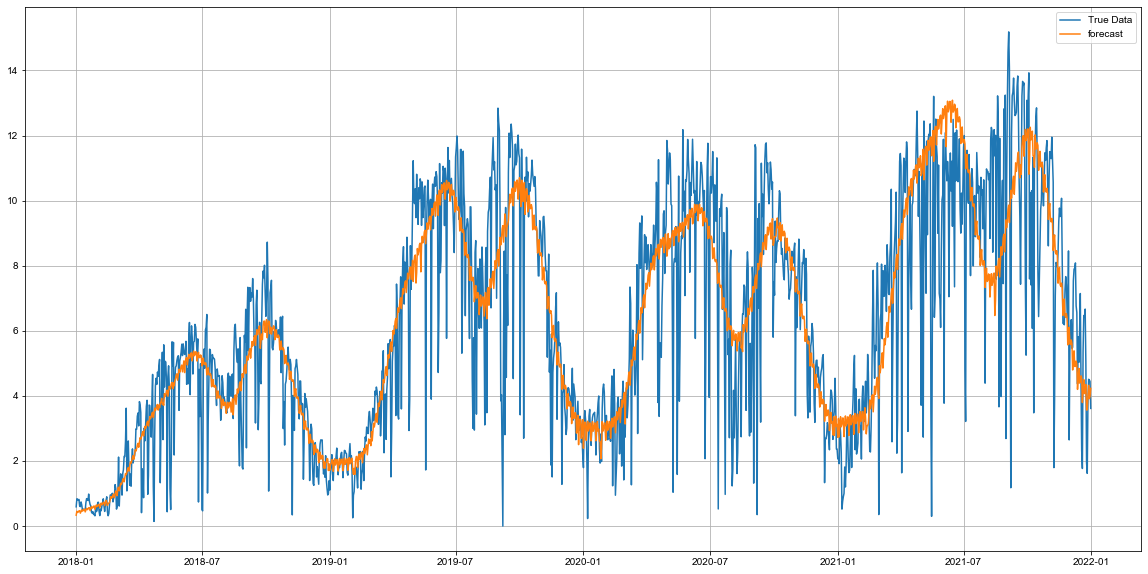

- 튜닝 후 완전 일그러졌던 2021년 데이터를 매우 높게 예측하고 있음.
- 트렌드도 하락 후 다시 증가하고 있는 추세로 잡아냄
각 지역구 모델 만들기
proh_광진구 = Prophet(changepoint_prior_scale=0.1,
seasonality_mode = 'multiplicative',
seasonality_prior_scale = 15,
daily_seasonality=True,
yearly_seasonality=5,
interval_width=0.9,
holidays=holidays_df,
holidays_prior_scale= 15
)
proh_성동구 = Prophet(changepoint_prior_scale=0.1,
seasonality_mode = 'multiplicative',
seasonality_prior_scale = 12,
daily_seasonality=True,
yearly_seasonality=5,
interval_width=0.9,
holidays=holidays_df,
holidays_prior_scale= 10
)
proh_동대문구 = Prophet(changepoint_prior_scale=0.1,
seasonality_mode = 'multiplicative',
seasonality_prior_scale = 15,
daily_seasonality=True,
yearly_seasonality=10,
interval_width=0.9,
holidays=holidays_df,
holidays_prior_scale= 15
)
proh_중랑구 = Prophet(changepoint_prior_scale=0.5,
seasonality_mode = 'multiplicative',
seasonality_prior_scale = 12,
daily_seasonality=True,
yearly_seasonality=5,
interval_width=0.9,
holidays=holidays_df,
holidays_prior_scale= 5
)모델 피팅 및 2022년 값 예측
proh_광진구.fit(df_광진구)
future_광진구 = proh_광진구.make_future_dataframe(periods=365, freq='D',include_history=False)
forecast_광진구 = proh_광진구.predict(future_광진구)
proh_동대문구.fit(df_동대문구)
future_동대문구 = proh_동대문구.make_future_dataframe(periods=365, freq='D',include_history=False)
forecast_동대문구 = proh_동대문구.predict(future_동대문구)
proh_성동구.fit(df_성동구)
future_성동구 = proh_성동구.make_future_dataframe(periods=365, freq='D',include_history=False)
forecast_성동구 = proh_성동구.predict(future_성동구)
proh_중랑구.fit(df_중랑구)
future_중랑구 = proh_중랑구.make_future_dataframe(periods=365, freq='D',include_history=False)
forecast_중랑구 = proh_중랑구.predict(future_중랑구)예측값 최종 submission에 저장
submission['광진구'] = forecast_광진구['yhat']
submission['동대문구'] = forecast_동대문구['yhat']
submission['성동구'] = forecast_성동구['yhat']
submission['중랑구'] = forecast_중랑구['yhat']
submission.tail()
후기
하이퍼 파라미터 튜닝 과정에서 시간이 너무 오래걸렸다.
시계열 데이터 분석은 처음이라 데이터를 쉽게 건드리기가 어려웠다. EDA 진행과정에서 월 중앙값을 기준으로 학습하게 된다면 시간이 크게 단축 될 수 있을 것 같다는 생각은 했는데 모델 정확도가 많이 떨어질 것 같았다.
그래도 이번 분석을 통해 이전에 했었던 따릉이 수요 예측에서 사용하지 않은 Prophet 모델을 사용하여 Prophet 사용법에 대해서 학습할 수 있는 좋은 기회였다.
'데이터분석' 카테고리의 다른 글
| Riot API 활용해서 TFT 시즌8 데이터 분석 해보기 - (1) 크롤링 (0) | 2023.03.03 |
|---|---|
| 최동원 선수 연봉 예측 프로젝트 (2) | 2023.01.12 |
| 스타벅스 매장은 정말 매장마다 차이가 없을까?? - (1) (0) | 2022.12.12 |
| 텍스트 마이닝 - Bag of words / TF-IDF (0) | 2022.12.12 |
| 이디야는 스타벅스 근처에 입점한다? (0) | 2022.11.25 |

