
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 원신
- 코사인 유사도
- 자연어 모델
- LDA
- 개체명 인식
- 피파온라인 API
- 붕괴 스타레일
- Tableu
- 데벨챌
- 토픽 모델링
- 블루 아카이브
- 클래스 분류
- 구글 스토어 리뷰
- KeyBert
- geocoding
- CTM
- 옵티마이저
- 포아송분포
- BERTopic
- 데이터넥스트레벨챌린지
- 문맥을 반영한 토픽모델링
- NLP
- 트위치
- Optimizer
- Roberta
- 블루아카이브 토픽모델링
- 다항분포
- 조축회
- SBERT
- 데이터리안
- Today
- Total
분석하고싶은코코
새로운 뉴스 기사 알람 본문
크롤링하고 새로운 뉴스 기사에 대한 알람을 보내주는 프로젝트를 진행했다.
원래는 GPT에 대한 기사를 요약해서 보내주려고 했지만 요약하는 부분까지 구현하기에는 너무 오래걸려서 새로운 기사가 있다면 그 기사에 대한 제목을 푸시해주는 프로젝트로 변경했다.
크론탭으로 스케줄링 해두면 새로운 기사를 찾고 새로운 기사가 있다면 제목을 텔레그램으로 푸시해준다.
지금은 제목만 보냈지만 url에 대한정보도 가지고 있으니 같이 푸시해주면 쉽게 볼 수 있을듯..? 제목에 하이퍼링크를 걸어서 GPT기사만 알람을 보내도록 했다. 알람은 3분마다 신규기사를 탐색하고 1분마다 수정됐는지 확인하고 수정됐다면 GPT기사를 필터링해서 알람을 보내도록 했다.
아래 코드는 제목만 알람을 보내주는 코드입니다.
수정내용
+ (4.18 수정) crawler는 뉴스 크롤링만을 담당하고 news는 푸시만 담당하도록 수정.
+ (4.18 수정) 크롤링한 기사를 보관하지 않도록 수정. 마지막 기사, 크롤링 시점만을 저장하도록 변경
+ (4.19 수정) 파일의 수정 정보를 받아와서 수정됐다면 알람을 보내도록 설정
+ (4.19 수정) 기사 업로드시 기자가 카테고리를 잘못 설정하여 우연히도 최신기사가 다른 카테고리로 변경된 경우가 발생했다. 그래서 이 부분을 해결하고자 4페이지까지 탐색해서 최신기사가 없으면 마지막 페이지를 4페이지로 강제 설정하게 함
코드
크롤링&PUSH(crawler.py)
import time
import numpy as np
import pandas as pd
import requests
from datetime import datetime, timedelta
import re
headers = {
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.1 ' \
'Safari/605.1.15'
}
# 각자 진행하는 카테고리에 맞게 수정하시면 됩니다. 코드는 직접 찾으셔야해요
category = {
#경제
'101' : ['258','259','260','261','262','263','310','771'],
#IT/과학
'105' : ['226','227','228','229','230','283','731','732']
}
# 코드 매칭
category_dict = {
'101' : '경제',
'105' : 'IT/과학',
#경제
'259' : '금융',
'258' : '증권',
'260' : '부동산',
'261' : '산업/제계',
'262' : '글로벌 경제',
'263' : '경제일반',
'310' : '생활경제',
'771' : '중기/벤처',
#IT/과학
'226' : '인터넷/SNS',
'227' : '통신/뉴미디어',
'228' : '과학/일반',
'229' : '게임/리뷰',
'230' : 'IT일반',
'283' : '컴퓨터',
'731' : '모바일',
'732' : '보안/해킹'
}
start_time = time.time()
# 마지막에 탐색한 기사 url정보를 통해 이번 탐색에서 어느 페이지까지 탐색해야할지 검사
def check_new_content(url, recent_url):
page = 1
while True:
contents_urls = getUrls(url+str(page))
if recent_url in contents_urls:
return url+str(page)
if page > 3:
return url+str(page)
page+=1
# 마지막 페이지의 번호를 반환
def getEndPage(url, recent_url):
if recent_url:
end_page_url = check_new_content(url, recent_url)
else:
end_page_url = f'{url}999'
print(end_page_url)
response = requests.get(end_page_url, headers=headers)
soup = bs(response.text, "html.parser")
return soup.select_one('#main_content > div.paging > strong').text
# 기사의 본문 탐색을 위해 URL들을 탐색하여 반환
def getUrls(url):
res = requests.get(url, headers=headers)
if res.status_code != 200:
print("page Request Error")
return
soup = bs(res.text, "html.parser")
now_urls =[]
for row in soup.select('#main_content > div.list_body.newsflash_body > ul > li'):
row = row.select_one('a')
now_urls.append(row['href'])
return now_urls
# 마지막 페이지 번호를 받아 탐색할 서비 카테고리 페이지 url을 만들어냄
def get_content_url(base_url, recent_url):
pages = [base_url+str(i) for i in range(1, int(getEndPage(base_url, recent_url))+1)]
urls = []
for page_url in pages:
urls += getUrls(page_url)
try:
if recent_url:
urls = urls[:urls.index(recent_url)]
except:
print("Recent URL Exist but Can't Searching Error!!" )
return urls
# 기사 본문 url을 받아 데이터 프레임에 내용 저장
def get_news_content(df, main, sub, platform):
time.sleep(0.1)
for idx, row in df.iterrows():
url = row['url']
response = requests.get(url, headers=headers)
soup = bs(response.text, "html.parser")
item = dict()
row['title'] = soup.select_one('#title_area > span').text if soup.select_one('#title_area > span') else ''
isWriter = soup.select_one('#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_journalist > a > em')
row['writer'] = isWriter.text if isWriter else ''
row['content'] = soup.select_one('#newsct_article').text if soup.select_one('#newsct_article') else ''
writed_at = soup.select_one('#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_info_datestamp > div > span')
row['writed_at'] = writed_at['data-date-time'] if writed_at else ''
row['main_category'] = main
row['sub_category'] = sub
row['platform'] = platform
# 메인 함수 이 함수를 통해 모든 작업이 진행 -> 새로운 기사의 DataFrame, 서브 카테고리별 최신 기사에 대한 정보를 반환
from tqdm import tqdm
def make_new_data():
recent_urls = read_recent_urls()
new_contents = pd.DataFrame()
try:
last_date = pd.to_datetime(recent_urls['last_date'])
print('Load last_date -> ', last_date)
except: # 파일이 없으면 오류가 발생하고 오늘 이전 날짜로 last_Date를 설정
last_date = pd.to_datetime(time.strftime('%Y%m%d', time.localtime()))
print('last_date create => ', last_date)
today = pd.to_datetime(time.strftime('%Y%m%d', time.localtime()))
num_cores = 8
# 탐색할 날짜 리스트를 먼저 생성합니다.
dates = [last_date]
while True:
if (last_date.day == today.day) & (last_date.month == today.month):
break
last_date = last_date + timedelta(days=1)
dates.append(last_date)
# 날짜 -> 카테고리1 -> 카테고리2
print('Serach from : ' + str(dates[0]) + 'to : ' + str(dates[-1]))
for main, sub_lst in category.items(): # 카테고리1 : 경제, IT/과학
for sub in sub_lst: # 카테고리2
for date in dates:
detail_date = date.strftime('%Y%m%d') # 20230201 형태
new_contents_sub = pd.DataFrame(columns={'main_category', 'sub_category', 'content', 'platform', 'source',
'title', 'writed_at', 'writer','url'})
url = f'https://news.naver.com/main/list.naver?mode=LS2D&mid=shm&sid2={sub}&sid1={main}&date={detail_date}&page='
print('BASE URL : ',url)
try:
recent_url = recent_urls[str(sub)]
except:
print("Can't find recent_url -> ", sub)
recent_url = ''
new_contents_sub['url'] = get_content_url(url, recent_url)
print('Crawling...')
get_news_content(new_contents_sub, main, sub, '네이버')
new_contents = pd.concat([new_contents_sub, new_contents])
# break
if len(new_contents_sub):
recent_urls[sub] = new_contents_sub.iloc[0]['url']
# break
# break
print('Searching Fin return contents!!')
return new_contents, recent_urls # news dataframe
# 크롤링 데이터 저장 함수
import json
def save_recent_urls(recent_urls):
with open('/home/ubuntu/news3/recent_urls.json','w') as f:
json.dump(recent_urls, f, ensure_ascii=False, indent=4)
def read_recent_urls():
recent_url = dict()
try:
with open('/home/ubuntu/news3/recent_urls.json','r') as f:
recent_url = json.load(f)
except:
print('Not exist recent_urls')
return recent_url
def load_crawled_contents(file_path):
try:
news = pd.read_csv(file_path, index_col=False)
return news
except:
return pd.DataFrame()
def save_news_data(file_path, new):
new.to_csv(file_path, index=False)
# 통합 클렌징 코드
def cleansing(text:str, writer:str=None) -> str:
# 특수기호 제거
text = re.sub('[▶△▶️◀️▷ⓒ■◆●©️]', '', text)
# ·ㆍ■◆△▷▶▼�"'…※↑↓▲☞ⓒ⅔
text = text.replace('“','"').replace('”','"')
text = text.replace("‘","'").replace("’","'")
# 인코딩오류 해결 (공백으로 치환)
text = re.sub('[\xa0\u2008\u2190]', ' ', text)
# URL제거를 위해 필요없는 문구 처리
text = text.replace('https://', '')
# 이메일 처리, URL 제거
# '[\w\.-]+(\@|\.)[\w\.-]+\.[\w\.]+'
text = re.sub('([\w\-]+(\@|\.)[\w\-.]+)', '', text)
# 기자 제거
# [~~~ 이데일리 ~~ 기자 ~~~]
if writer:
left_s, right_s, not_left, not_right = ('[\(\{\[\<]', '[\)\}\]\>]', '[^\(\{\[\<]', '[^\)\}\]\>]')
text = re.sub('%s%s+%s%s+?%s'%(left_s, not_right, writer, not_left, right_s), '', text)
# ., 공백, 줄바꿈 여러개 제거
# \s -> 공백( ), 탭(\t), 줄바꿈(\n)
text = re.sub('[\.]{2,}', '.', text)
text = re.sub('[\t]+', ' ', text)
text = re.sub('[ ]{2,}', ' ', text)
text = re.sub('[\n]{2,}', '\n', text)
return text
import pip
def install(package):
if hasattr(pip, 'main'):
pip.main(['install', package])
else:
pip._internal.main(['install', package])
# 메인 함수
import asyncio
import sys
if __name__ == '__main__':
print("-"*30)
location_time = time.localtime()
print(f'Running Start : {str(location_time.tm_hour)} : {str(location_time.tm_min)}')
print("-"*30)
try:
from bs4 import BeautifulSoup as bs
except:
print('Install BS4')
install('beautifulsoup4')
from bs4 import BeautifulSoup as bs
# 뉴스 데이터
print('Crawling Start')
# crawled_contents = load_crawled_contents('./news.csv') # 기존의 기사가 있는지 확인하고 있다면 불러옴. 없으면 빈 DataFrame 가져옴
new_contents, recent_urls = make_new_data() # 새로운 기사 탐색
print('Crawling Fin')
# 현재 시간 넣기
last_date = time.strftime('%Y%m%d', time.localtime())
recent_urls['last_date'] = last_date
# 새로운 기사 본문 클렌징
# print('Cleansing Start...')
# new_contents['content'] = new_contents['content'].apply(cleansing)
# print('Cleansing Fin')
print(f'New Content {len(new_contents)}')
print(f'Running Time : {time.time() - start_time}')
# 모든 작업이 끝났으니 지금까지 데이터 저장
save_recent_urls(recent_urls)
save_news_data('/home/ubuntu/news3/news.csv', new_contents)
텔레그램 초기화(news.py)
import pandas as pd
def read_data(file_path):
return pd.read_csv(file_path)
def preprocessing(df):
# 전처리
# return df
pass
def select_topic(df):
flags = (df['content'].str.contains('gpt')) | (df['content'].str.contains('GPT')) |\
(df['content'].str.contains('챗')) | (df['content'].str.contains('자연어'))
return df[flags].reset_index(drop=True)
def summarize(df):
# df['content'] 요약
# return df['summarized_text']
pass
import asyncio
class TelegramManager:
def __init__(self):
pass
async def init_bot(self):
self.token = '텔레그램 토큰' # 받는게 맞나?
self.bot = telegram.Bot(self.token)
self.chat_id = '알람 받을 ID' # 숫자형태
async def send_msg(self, text):
if text == '':
print('None GPT Contents')
return
try:
print(self.chat_id)
for sending_id in self.chat_id:
print(sending_id)
self.bot.sendMessage(chat_id = sending_id, text = text, parse_mode = 'Markdown')
except Exception as e:
print(e)
return
async def init_telegram():
bot = TelegramManager()
await bot.init_bot()
return bot
async def send_msg(bot, topics):
send_text = ''
for idx, row in topics.iterrows():
main_text = row['title']
url = row['url']
writed_at = '(' + row['writed_at'] + ')\n\n'
send_text += f"[{main_text}]({url})" + writed_at
await bot.send_msg(send_text)
import pip
def install(package):
if hasattr(pip, 'main'):
pip.main(['install', package])
else:
pip._internal.main(['install', package])
import os
import json
def isModify():
last_modify = os.path.getmtime('/home/ubuntu/news3/news.csv')
try:
with open('/home/ubuntu/news3/save_modify_time.json','r') as f:
save_modify_time = json.load(f)['modify_time']
except:
save_modify_time = 0
modify_time_dict = dict()
if last_modify > save_modify_time:
print('Modify csv file')
modify_time_dict['modify_time'] = last_modify
result = True
else:
print('Not Modify csv file')
modify_time_dict['modify_time'] = save_modify_time
result = False
with open('/home/ubuntu/news3/save_modify_time.json','w') as f:
json.dump(modify_time_dict, f, ensure_ascii=False, indent=4)
return result
import time
import sys
if __name__ == '__main__':
start_time = time.time()
print("-"*30)
location_time = time.localtime()
print(f'Running Start : {str(location_time.tm_mon)} - {str(location_time.tm_mday)} / {str(location_time.tm_hour)} : {str(location_time.tm_min)}')
print("-"*30)
if isModify():
try:
import telegram
except:
print('Install Telegram')
install('python-telegram-bot')
import telegram
csv_path = '/home/ubuntu/news3/news.csv'
new_contents = read_data(csv_path)
if len(new_contents) == 0:
print('No Contents')
else:
# 키워드 뉴스 뽑아내기
topics = select_topic(new_contents)
print('GPT ARTICLE : ', len(topics))
# 전처리
# topics = preprocessing(topics)
# # 요약
# summarize = summarize(topics)
# 텔레그램
loop = asyncio.get_event_loop()
push_article = loop.run_until_complete(init_telegram())
loop.run_until_complete(send_msg(push_article, topics))
loop.close()
#delete csv
# if os.path.isfile(csv_path):
# print('Remove CSV')
# os.remove(csv_path)
print()
print(f'Running Time : {time.time() - start_time}')
텔레그램 알람 화면
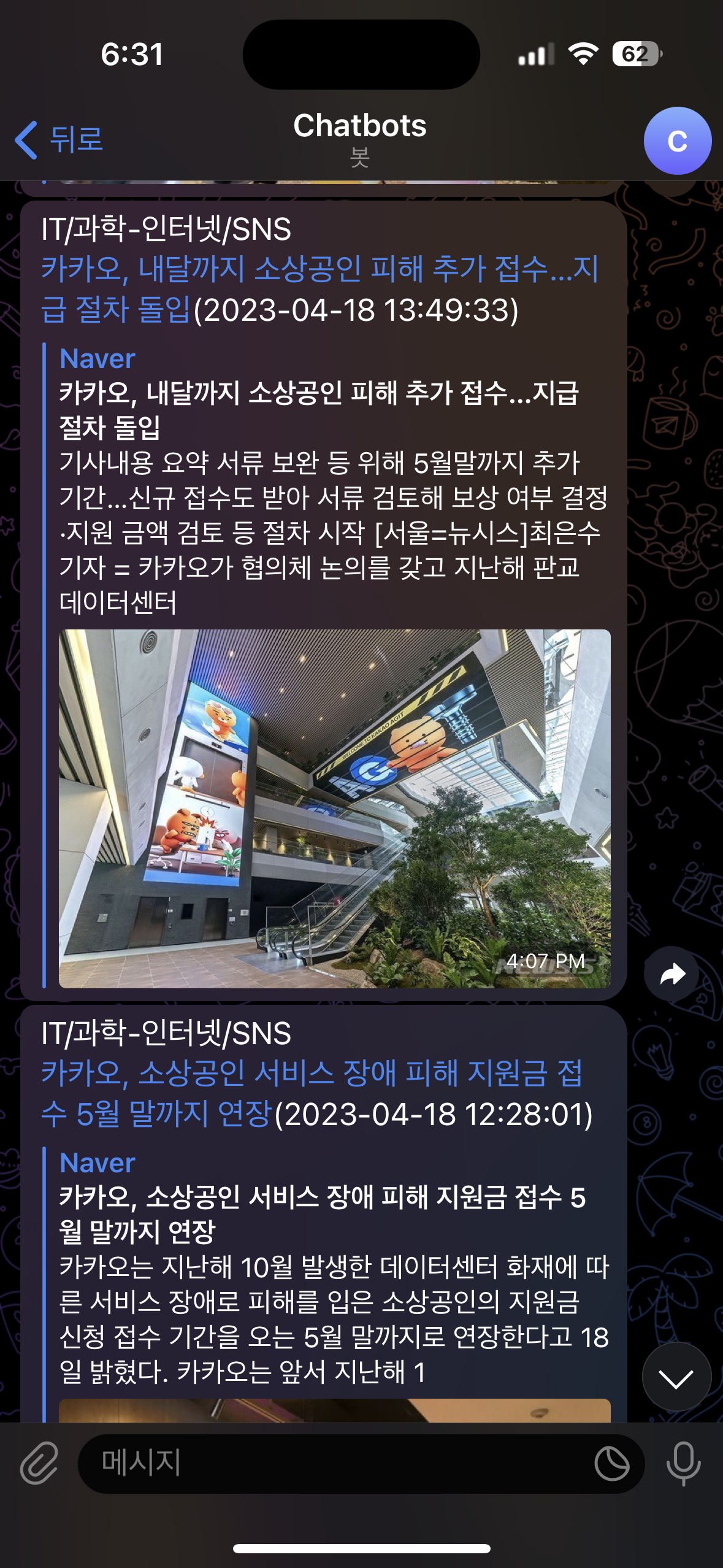
이번 프로젝트 진행하면서 특정 기사에 대한 필터링을 하지는 않았지만 실시간으로 새로운 기사에 대한 알람을 받아보는 작업을 구현해봤다.
크롤링이 단순하다고만 생각했는데 이번 프로젝트를 진행하면서 크롤링으로도 생각해야할 부분이 많다는걸 느낄 수 있었다.
게임쪽에 적용해본다면 아마 특정 커뮤니티에 대해서 탐색 스케줄링을 해두고 버그, 악용 등 크리티컬한 키워드가 들어간 게시글이 올라왔을때 알람을 보내주는 방식이면 되지 않을까 싶다. 아니면 30추글, 개념글 등 많은 유저들이 보고 있는 게시글에 대해서 푸시를 해주면 유저들의 어떤것들에 관심이 있는지 알 수 있는 정보가 될 수 있을것 같다. 물론 어그로성 글인지 판단할 수 있는 방법이 있을까 싶긴하지만.... 다음에 시간이 여유있을때 한 번 진행해봐야겠따!!
'Python > 크롤링' 카테고리의 다른 글
| Python Free Proxy 사용하기 (0) | 2023.05.09 |
|---|---|
| BeautifulSoup을 이용한 네이버 뉴스 크롤링(Multiprocessing) (0) | 2023.03.22 |
| Riot API 사용 간단 정리 (0) | 2023.02.16 |
| Geocoding - 네이버 API (0) | 2023.02.12 |

