
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 옵티마이저
- BERTopic
- 구글 스토어 리뷰
- 조축회
- SBERT
- 피파온라인 API
- 블루 아카이브
- 붕괴 스타레일
- 블루아카이브 토픽모델링
- NLP
- LDA
- 데이터리안
- KeyBert
- Roberta
- geocoding
- 데이터넥스트레벨챌린지
- 토픽 모델링
- Tableu
- 코사인 유사도
- 원신
- CTM
- 데벨챌
- 문맥을 반영한 토픽모델링
- 자연어 모델
- 개체명 인식
- 트위치
- 포아송분포
- 다항분포
- 클래스 분류
- Optimizer
- Today
- Total
분석하고싶은코코
RL(강화학습) 이해하기_Q-learning 본문
RF(Reinforcement learning)에 대해서 이해하는 과정에 대한 페이지로 여러 시리즈로 작성할 예정입니다. 당장의 RF에 대한 이해보다는 RF라는 분야에 대해서 천천히 알아가는 과정의 시리즈 입니다. 이 시리즈는 복잡한 수식에 대한 이해보다는 과정에 대한 이해를 중점으로 두고 있습니다.
강화학습을 이해하기 좋은 대표적인 알고리즘은 Q-learning알고리즘입니다. 이 알고리즘은 쉽게 말하자면 목적지까지 Greedy한 선택하여 경로를 찾는 방법입니다. Greedy란 탐욕적으로 큰 값을 찾아가는 의미입니다. 그런데 이 알고리즘은 출발 지점에서 내가 지나온 거리에 대한 정보를 담고 목적지까지 찾아가는게 아니라 역으로 계산합니다. 즉, 찾고자하는 'Goal' 목적지가 있는데 도착하게 되면 Reward라는 보상값이 있는데 이를 통해 경로를 업데이트 하게 됩니다. 즉 '현재 타일에 대한 업데이트는 다음 타일에 영향을 받고, 다음 타일에 대한 선택은 지금 타일 중 Greedy하게 선택한다'로 이해하시면 됩니다. 이를 반복하면서 타일을 업데이트 하는 것입니다.
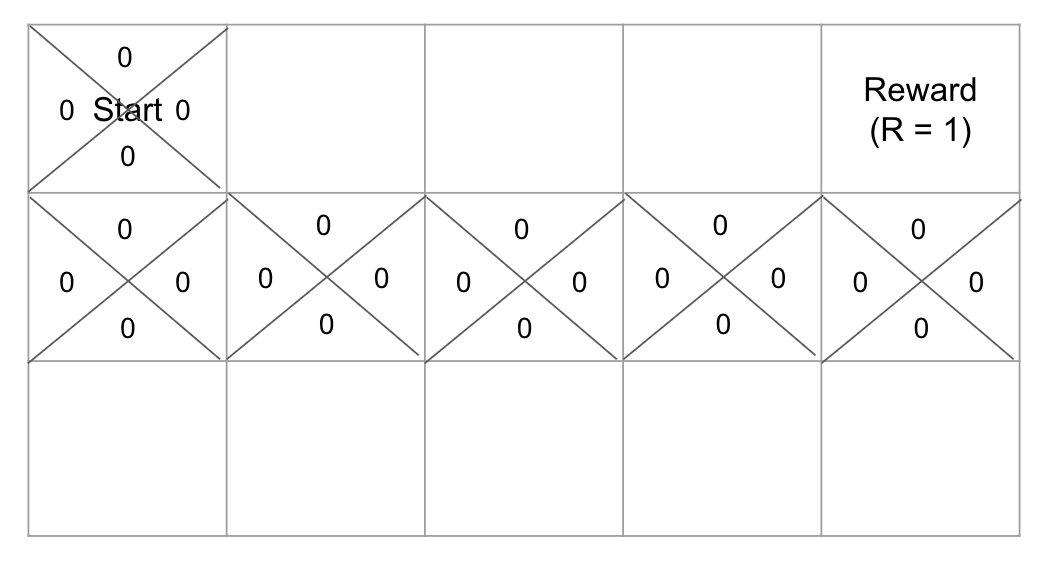

앞서 이야기했듯 Q-learning은 지금 내 행동에 대한 값이 아니라 다음 값을 통해 업데이트가 이뤄집니다. 그렇기에 초기에는 모두 같은 값으로 초기화가 되어 있어 선택을 랜덤하게 할 수 밖에 없었습니다. 랜덤하게 선택된 경로가 위와 같은 경로를 찾게 된 것이죠. 그래도 목적지까지 가는 타일의 선택이 랜덤하게 됐지만 여차저차 목적지까지 도달하는 길을 찾았습니다. 그런데 해당 학습 과정은 Greedy한 선택을 하게 됩니다.
자, 이제 한 번 목적지까지의 경로를 찾았으니 끝일까요? 아니죠 다른 경로도 찾을 필요성은 있습니다. 그런데 다른 경로를 찾아보기 위해 다시 출발지점부터 경로 탐색을 한다면? 당연히 Greedy한 선택을 하기 때문에 처음 찾은 목적지까지의 경로만을 계속 탐색하게 됩니다. 이때 들어가는게 엡실론(ε)이라는 값이 들어가게 됩니다. ε은 맨처음 선택한 랜덤한 경로 탐색의 확률을 나타냅니다. Greedy선택이 아니라 Random선택하게 되는 것이고 이것을 통해서 새로운 경로를 찾게 되는 것이죠. 그런데 ε이 너무 크면 충분한 학습이 됐음에도 계속 랜덤한 경로를 찾기 때문에 문제가 발생하게 되겠죠. 이를 방지 하기 위해 초기 ε을 큰 값으로 설정하여 최대한 많은 경로를 찾게 학습시키고 Decaing하여 ε값을 점차 줄여 나중에는 최적의 경로를 잘 선택하게끔 설정할 수 있습니다. 머신러닝, 딥러닝 과정에서 나온 과소적합에서 과적합으로 바뀌는 과정이라고 이해하시면 편하실 것 같습니다. 이를 통해서 1열의(->) 단방향 경로를 새로 찾았다고 가정해보겠습니다.
(이 과정에서 또 하나의 이점이 존재하는데 원래 생각했던 목적지보다 더 좋은 Reward를 갖고 있던 목적지를 찾아낼 수 있다는데 있습니다.)

자, 그러면 여기서 발생하는 문제는 또 무엇일까요? Greedy한 선택으로 업데이트를 진행했기 때문에 어디가 최적의 경로인지를 알 수가 없습니다. 그렇다면 이를 알기위한 값이 필요하겠죠? 그게 바로 감마(γ)입니다. γ값은 0에서 1사이의 값을 갖는 값으로 목적지에서 부터 출발지점까지의 경로의 타일이 움직일때마다 값이 곱해지게 되는데 다음과 같이 타일이 업데이트 됩니다. (현재 경로는 첫번째 열에서 단방향, 위 그림에서 봤던 'ㄴ'자형 경로 두 가지의 경로를 찾았음을 가정합니다.)
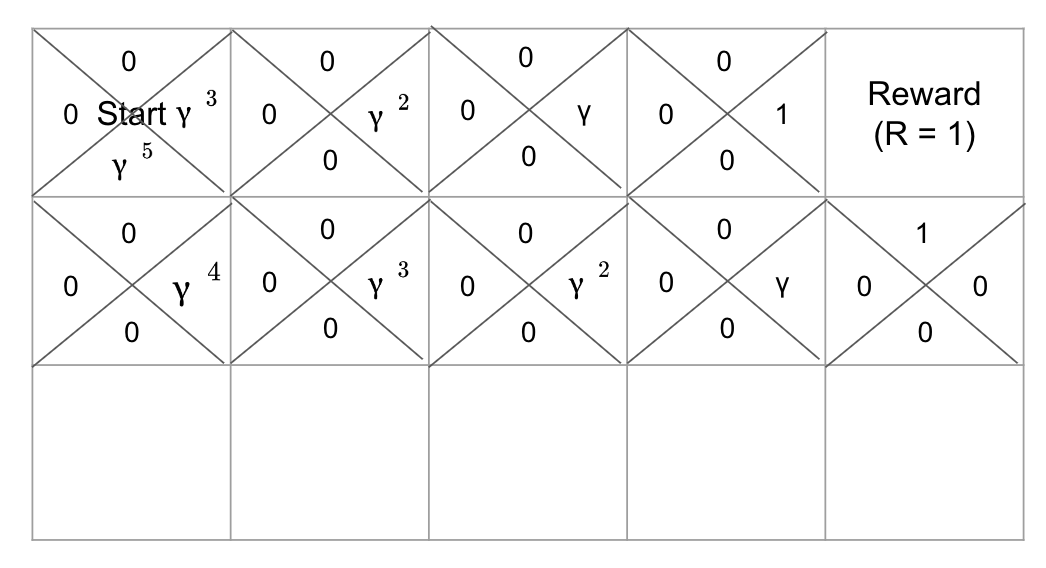
이렇게 되면 찾은 경로는 2가지가 있는데 그 중에서 뭐가 최적인지 알 수있게 되고 ε값이 작아짐에 따라 해당 타일에서 경로를 찾는 방법은 γ의 값을 통해서 찾게 되겠죠. 그러면 이를 확률식으로 표현하게 된다면 P(a_t | s_t)가 됩니다. (여기서a는 action으로 방향 선택을 의미하고 s는 state로 타일을, t는 각 시점을 뜻합니다.) 이를 우리는 Policy(정책)이라고 표현합니다. 이 과정은 모든 타일에서 똑같이 표현 됩니다. 이를 통해서 타일을 업데이트하게 되는 것이죠.
이렇게 하면 Q-learning에 대한 알고리즘의 일부를 이해하신겁니다. 이러한 과정에서 두가지 Function이 존재하는데 이 부분에 대해서도 잠깐 이야기해보겠습니다. 두 가지 함수는 아래와 같습니다.
1. State Value Function
2. Action Value Function
두 가지 개념이 등장하는데 State는 타일을 의미하고 Action은 방향 선택을 의미합니다. Value Function이란 지금 시점에서의 기대값을 의미합니다. 즉, State Value Function은 타일을 기준으로 목적지까지의 기대값을 의미하고 Action Value Function은 지금 시점(타일)에서 내가 선택한 방향에 대한 목적지 기대값을 의미합니다. 그렇다면 State가 Action보다 상위 개념이라는 것을 이해하실 수 있으실 겁니다. 그런데 앞서 설명한 Policy는 State Value Function에서 가장 큰 값을 찾는 Greedy한 선택을 하게 됨으로서 최적의 경로를 찾을 수 있게 되는 것입니다. 이를 Optimal Policy라고 합니다.
'머신러닝&딥러닝 > RF(강화학습)' 카테고리의 다른 글
| RLHF_Chatbot 만들기(던전앤파이터 Chatbot) (1) | 2024.01.31 |
|---|---|
| PPO 구현을 위한 TRL패키지 살펴보기 (0) | 2024.01.31 |
| RLHF모델 실습(1)_데이터 수집 및 정제_던전앤파이터 챗봇 만들기 (0) | 2024.01.19 |
| RLHF(Reinforcement Learning from Human Feedback)_(3) - PPO (0) | 2024.01.18 |
| RL(강화학습) 이해하기_PPO(Proximal Policy Optimization) (1) | 2024.01.13 |

