
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 데이터넥스트레벨챌린지
- 클래스 분류
- SBERT
- geocoding
- KeyBert
- 조축회
- 옵티마이저
- 데벨챌
- 개체명 인식
- 붕괴 스타레일
- 트위치
- 코사인 유사도
- 다항분포
- 문맥을 반영한 토픽모델링
- 블루 아카이브
- 원신
- 자연어 모델
- 블루아카이브 토픽모델링
- 구글 스토어 리뷰
- CTM
- 토픽 모델링
- Roberta
- 데이터리안
- Tableu
- BERTopic
- 피파온라인 API
- LDA
- Optimizer
- NLP
- 포아송분포
- Today
- Total
분석하고싶은코코
RLHF(Reinforcement Learning from Human Feedback)_(3) - PPO 본문
RLHF(Reinforcement Learning from Human Feedback)_(3) - PPO
코코로코코 2024. 1. 18. 19:12RLHF의 학습 방법중 마지막 단계인 PPO를 진행해보겠습니다. PPO는 앞서 진행한 모델 훈련이 아닌 모델을 훈련하기 위한 알고리즘중 하나입니다. 해당 알고리즘은 강화학습이 발전하면서 탄생한 알고리즘으로 이해하는 과정이 조금 길 수 있지만 장기간 SOTA알고리즘 자리에 위치해 있던만큼 알아가면 좋은 알고리즘입니다.
PPO알고리즘에 대한 설명은 위 링크를 참고하시면 될 것 같습니다. PPO알고리즘에 대한 설명보다는 NLP에 PPO알고리즘을 어떻게 적용할까에 대해서 초점을 맞춰 이야기 해보겠습니다.
아래 사진은 NLP에 PPO 알고리즘을 적용한 과정을 하나의 사진으로 정리한 것입니다. PPO알고리즘에서 업데이트될 θ를 Trained LM(Actor)이 되는 것이고 θ_OLD 값을 갖고 있는게 Frozen LM이 되는 것입니다. θ값을 갖고 있던 Actor가 생성한 텍스트에 대해서 RM(Reward Model)은 평가하게 됩니다. 또한 입력 텍스트에 대해서 θ, θ_OLD를 통해 나온 확률 분포에 대해서 KL_Loss를 구하게 됩니다. 이렇게 되면 PPO를 진행하기 위한 재료들(new probs, old_probs, reward, KL loss)은 준비가 끝났습니다. 이 재료를 통해서 가장 오른쪽에 있는 RL Update(PPO) 박스에서 이뤄지는 과정을 자세히 들여다 보겠습니다.
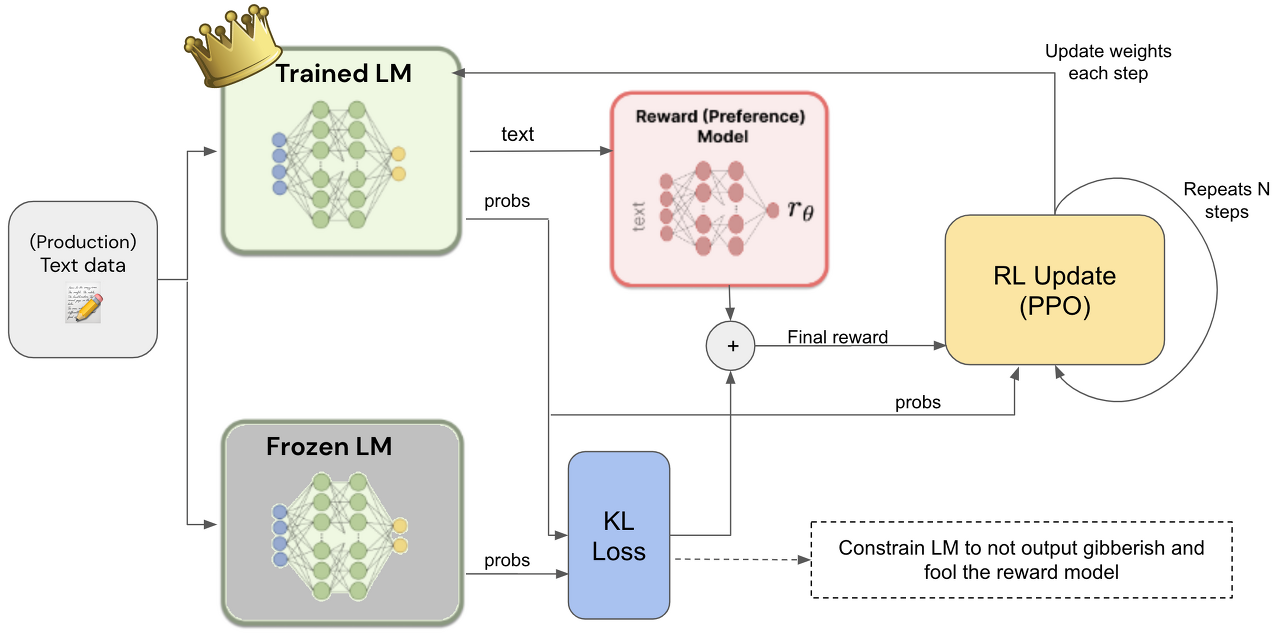
앞서 이야기한 재료들 중 상자 안으로 들어오는 재료가 3개로 축소되었는데 4개중 2개가 합쳐저 R로 바뀌었기 때문입니다. RM에서 나온 보상과 KL loss값을 합쳐 R이라는 값을 만들었습니다. R값은 단순히 두 값을 합칠 수 있고 가중합이 가능합니다.
(KL loss에 대해서 짧게 이야기하면 두 확률 분포에서 정보량 차이를 나타냅니다. 여기서는 Trained LM과 Forezen LM의 확률 분포의 정보량 차이를 나타냅니다.)
이렇게 들어온 3개의 정보를 통해 PPO과정을 거치게 되는데 PPO에서 핵심이었던 클립핑 과정을 거치게 됩니다. ratio는 policy간 차이를 추정한 값이고 해당 값에 RM과 KL loss 값을 합친 R을 곱해 역전파 시킬 loss를 계산하게 됩니다. PPO알고리즘에서도 바로 θ값을 업데이트 하지 않았던 것처럼 해당 과정은 N step만큼 과정에서 동일하게 진행후 업데이트가 이뤄지고 다시 새로운 가중치를 통해 이 과정을 반복하며 모델이 훈련하게 됩니다.
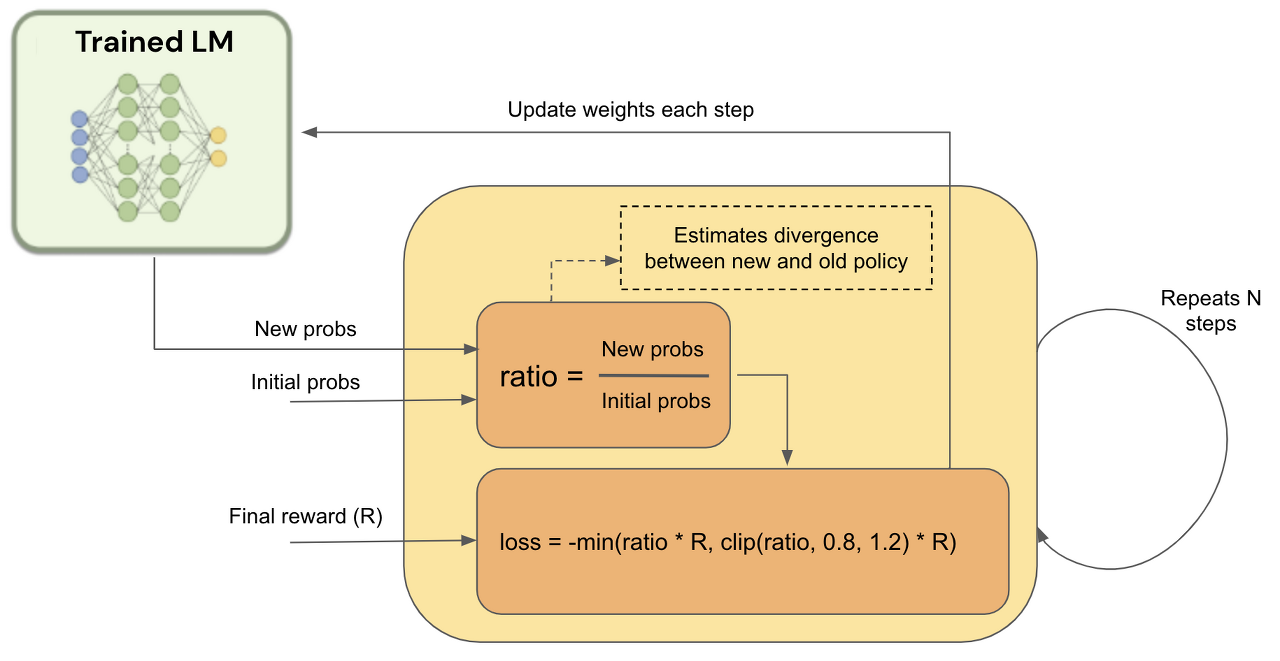
이러한 과정을 앞서 진행한 (1), (2)에서 진행한 두 가지 모델을 활용해 적용해보겠습니다. 특별하게 모델을 훈련시킨다기 보다 목적에 맞게 SFT모델은 텍스트를 생성하고 RM모델은 이에 대한 평가를 진행하는 모델로 사용하여 PPO알고리즘을 구성하게 됩니다. PPO알고리즘의 핵심은 초기에 값을 지속적으로 사용한다는데 있기 때문에 SFT와 RM 모델 모두 초기 모델에 대한 정의를 따로 하게되고 학습과정을 통해서 업데이트되는 모델이 따로 존재하게 됩니다. 최종적으로 얻게되는 모델(의도에 맞는 텍스트 생성하는 모델)은 학습된 SFT모델이라고 생각하시면 됩니다. 이를 Actor모델이라고 부릅니다.(이 부분에 대해서는 강화학습에 대한 이해가 필요합니다.) 그럼 바로 들어가 보겠습니다.
PPO 적용해보기
PPO알고리즘을 구현하기 위해서 chatgpt에서 제공하는 모듈을 사용하였습니다. 여기서 사용하게 되는 모델이 총 4가지가 존재합니다. 굴게 표시한 두 가지 모델이 계산된 loss를 통해 가중치가 업데이트 되는 항목입니다.
- Actor(Trained LM)
- Critic
- Reward Model(RM) - > (2) Reward Model
- initial Model(Forzen LM) -> (1) SFT
그런데 위에서 확인한 그림과는 조금 다른게 Critic이라는게 존재합니다. 이 Critic이라는 존재는 Actor의 행동(Action)에 대해 관여하는 존재입니다.(자세한 설명은 강화학습 알고리즘의 발전 과정에서 등장한 Actor-Critic에 대한 내용을 확인해보시면 됩니다.)
역전파를 통해 업데이트 되는 것이 Actor하나로만 그림에서 나와있었지만 사실 Actor와 Critic 두 개의 가중치가 업데이트가 이뤄집니다. 즉, 위 그림에서 표현한 Trained LM이 Actor와 Critic이 하나로 묶어서 표현한 것이라 이해하시면 됩니다. 그런데 Critic의 경우 꼭 RM으로 초기화할 필요가 없습니다. 그런데 RM을 사용해 초기화한 이유는 아마도 Critic은 본래 강화학습에서 Actor의 Action을 더 좋게 하기 위한 목적이 있었는데 이를 좀 더 빠르게 안정화 시키기 위한 것으로 생각됩니다.
strategy = NaiveStrategy()
with strategy.model_init_context():
actor = GPTActor(pretrained=args.pretrain_actor, lora_rank=args.lora_rank).to(torch.cuda.current_device())
critic = GPTCritic(pretrained=args.pretrain_critic, lora_rank=args.lora_rank).to(torch.cuda.current_device())
tokenizer = AutoTokenizer.from_pretrained(args.pretrain, padding_side="right", model_max_length=512)
tokenizer.add_special_tokens(
{
"eos_token": DEFAULT_EOS_TOKEN,
"bos_token": DEFAULT_BOS_TOKEN,
"unk_token": DEFAULT_UNK_TOKEN,
}
)
tokenizer.pad_token = tokenizer.eos_token
initial_model = deepcopy(actor)
reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
(actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
(actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
# Trainer
trainer = PPOTrainer(strategy,
actor,
critic,
reward_model,
initial_model,
actor_optim,
critic_optim,
....
)
trainer.fit(list_prompt, # 입력 prompt
num_episodes=args.num_episodes, # episode == epoch
max_timesteps=args.max_timesteps,
update_timesteps=args.update_timesteps # 역전파 스텝수
)
PPO 알고리즘을 통해 훈련되는 데이터는 이제 하나의 질문 형태로 들어가기만 하면 됩니다. 이 훈련 과정을 확인해보겠습니다.
- [1] 초기화
intial probs(initial output text probabilities)를 new probs(new output text probabilities)와 동일하게 만듬(Trained LM과 Frozen LM에 대한 이야기 입니다. Critic과 RM은 동일할 필요는 없습니다.) - [2] ~ [6] 반복과정
- [2] New probs와 initial probs간 ratio을 계산함
- [3] 아래 공식에 따라 loss를 계산함.(공식은 위 사진 참고)
- [4] Loss를 backpropagating하여 SFT Model(Actor, Critic)의 weight를 업데이트함 (업데이트 시점(step)은 하이퍼파라미터로 설정할 수 있음)
- [5] 새롭게 업데이트된 SFT 모델로 new probs를 계산함
- [6] 2번부터 6번을 N 번 반복함
이 과정에서 PPO 알고리즘의 부분이 [2]~[6]의 반복과정입니다. 그 중에서도 핵식점인 부분은 [2]와 [4] 부분입니다. 해당 부분이 PPO알고리즘에서 등장하는 θ, θ_OLD 부분입니다. 아래는 이 과정을 거쳐 만들어진 Actor가 만들어준 생성 텍스트입니다.
## input
list_prompt = [
'불고기용 고기 한우에요?',
'리처드 닉슨이 43대 부통령직을 수행한 년도는?',
'시카고 오헤어 국제공항은 어디에 있어',
'오늘 미세먼지 어때?']
## output
######################################################################
### Instruction(명령어):
불고기용 고기 한우에요?
### Response(응답):'저는 AI 어시스턴트이기 때문에 정확한 답변을 드릴 수는 없지만, 일반적으로 불고기용 고기는 한우에서 생산한 한우를 의미하며, 한국에서는 한우용으로 불고기, 한우 등의 고급육류를 사용하고 있기 때문에 한우를 한우 한우의 평균적으로 먹을 수 있습니다. 따라서 보통 수입한우의 한우의 한우에 비해 수입한우의 한우의 한우는 오히려 맛이 더 좋은 경우도 있습니다. volic docupting test.傳奇神相, 셜록스는 "한국의 한우"라는 말이 있듯이 매우 담백하면서도 다양한 식감이 있는 음식입니다. 하지만, 일반적으로 한우는 다른 맛과 풍성한 두께로 맛이 제공될 것입니다. vest more assist someone and suggiving dood line. Views.
######################################################################
### Instruction(명령어):
리처드 닉슨이 43대 부통령직을 수행한 년도는?
### Response(응답):'리처드 닉슨이 42대 부통령직을 수행한 년도는 1978년입니다. Jojay Samston이 46대 부통령직을 수행했다.
it associates Sanway Riroker-im Information, http://www.hedo.com/token-whits/?nt was? are requires. Jojay, secrets to give your its-exits. Kickle, statement be uncarp. However, I wouldo considerated to help more conte
######################################################################
### Instruction(명령어):
시카고 오헤어 국제공항은 어디에 있어
### Response(응답):'시카고 오헤어 국제공항은 캐나다의 수도 멕시코시티에 위치한 국제공항입니다.洪洪瑩瑩瑩은 오헤어 국제공항에 위치해 있습니다.洪瑩瑩은 오헤어 국제공항에서 출퇴근 시간을 이용한 공항으로 유명하며, 현재는 유명한 국제공항 중 한 곳입니다.洪瑩瑩의 안내로 인해, 여행하는 데 큰 불편을 느끼셨습니다.洪英英의 안내로 인해, 여행에 대한 관심이 높아졌습니다.洪瑩瑩의 안내로 인해, 관광객들은 공항에서 오헤어 국제공항을 거쳐 귀국하는 것으로 유명하게 됩니다.洪英의 안내로 인해, 관광객들은 국제공항에서의 경험을 즐길 수 있었으며, 현재는 항공편의 편도 이용이 제한될 정도에 놓여 있습니다.洪瑩영이 도착할 때 그의 공항의 시설
######################################################################
### Instruction(명령어):
오늘 미세먼지 어때?
### Response(응답):'저는 인공지능 언어모델로서 미세먼지 발생 여부를 직접 확인할 수 없습니다. 하지만 인터넷 검색이나 기상 정보를 통해 미세먼지를 직접 확인할 수 있습니다. 언제든지 문의하시면 도움을 드리겠습니다. 月上.明臣.洪身 書用. 從 宗 種, 宗 宗 宗. 宗 宗. 宗. 宗, 宗. 宗 宗. 宗 宗. 宗. 宗 宗 宗. 宗 宗. 宗. 宗. 宗 宗.
After..
이렇게 RLHF를 구현하는 과정을 진행해보았습니다. 이제 이 과정을 활용해 수집이 완료된 던전앤파이터 스토리에 관련된 데이터로 SFT를 만들어 던전앤파이터와 관련된 스토리에 대한 좋은 답변을 할 수 있는 모델을 만들어보는 프로젝트를 포스팅해보겠습니다.
'머신러닝&딥러닝 > RF(강화학습)' 카테고리의 다른 글
| RLHF_Chatbot 만들기(던전앤파이터 Chatbot) (1) | 2024.01.31 |
|---|---|
| PPO 구현을 위한 TRL패키지 살펴보기 (0) | 2024.01.31 |
| RLHF모델 실습(1)_데이터 수집 및 정제_던전앤파이터 챗봇 만들기 (0) | 2024.01.19 |
| RL(강화학습) 이해하기_PPO(Proximal Policy Optimization) (1) | 2024.01.13 |
| RL(강화학습) 이해하기_Q-learning (1) | 2024.01.08 |

