
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 붕괴 스타레일
- 원신
- 클래스 분류
- 블루아카이브 토픽모델링
- BERTopic
- 개체명 인식
- 다항분포
- 포아송분포
- 피파온라인 API
- 블루 아카이브
- 옵티마이저
- CTM
- NLP
- 조축회
- 데이터리안
- 데벨챌
- 데이터넥스트레벨챌린지
- 토픽 모델링
- 자연어 모델
- LDA
- Optimizer
- Tableu
- KeyBert
- Roberta
- 트위치
- 코사인 유사도
- 구글 스토어 리뷰
- SBERT
- geocoding
- 문맥을 반영한 토픽모델링
- Today
- Total
분석하고싶은코코
NLP - 텍스트랭크(TextRank) 본문
텍스트랭크(TextRank)는 페이지랭크(PageRank) 알고리즘에 기반하여 만들어진 자연어처리 방법입니다. 그렇다면 페이지랭크가 무엇인지 이해를 해야 텍스트랭크에 대해서 쉽게 이해할 수 있겠습니다. 그래서 이번 포스팅에서는 페이지랭크에 대해서 알아보고 이를 활용한 텍스트랭크에 대해서도 알아보겠습니다.
1) 페이지랭크(PageRank)
페이지랭크는 구글의 검색엔진의 핵심 알고리즘입니다. 구글에 내가 원하는 정보를 얻기 위해 검색해본 경험이 없는 사람은 없을 것 같습니다. 그렇다면 내가 키워드를 입력했을때 나오는 페이지들이 있는데 이 페이지들이 어떻게 보여지는가를 생각해보셨나요? 특히 구글을 검색하는 이유를 생각해보면 웹상에 존재하는 많은 사이트들의 다양한 결과를 받아볼 수 있기 때문일 것입니다. 그런데 다양하기 때문에 페이지 수가 엄청 날 것입니다. 적게는 천개 많게는 수만개의 웹사이트가 존재할텐데 어떻게 내가 원하는 키워드의 사이트를 보여주는 것일까요? 그를 결정하는 것이 페이지랭크 알고리즘입니다. 페이지랭크 알고리즘은 내가 검색한 키워드가 아닌 웹사이트들간의 관계로 가지고 점수(Score)를 측정해두고 순서를 나열해 결과를 보여줌으로서 가능성이 높은 페이지들을 보여주게 됩니다. 그렇다면 이 페이지링크가 어떻게 동작하는지 간단하게 알아보겠습니다.
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
우선 A라는 페이지의 페이지랭크를 구하는 식에 대해서 바로 보여드렸습니다. 그 이유는 이 식을 이해하면 페이지랭크 알고리즘을 모두 이해한 것이기 때문입니다. 우선 식에서 사용한 용어는 다음과 같습니다.
- PR = PageRank
- d = Damping Factor
- T = Page of indicate to A
- C = Count
식을 이해하기 앞서 d에 해당하는 Damping Factor는 나중으로 미루고 이해해보겠습니다. (1-d)이후에 있는 식은 A라는 페이지에 대한 페이지랭크는 A페이지를 가리키는 페이지들의 페이지랭크값들의 합을 의미합니다. 그런데 각 페이지랭크를 T를 카운트한 것으로 나눈 것이 보입니다. 이는 해당 페이지에서 링크된 다른 모든 페이지들을 카운트하는 것입니다. 즉, 다른 페이지에서 마구잡이로 링크를 걸어두었고 A페이지도 그중 하나라면 해당 페이지에서 얻는 값은 작아지는 것이죠. 이게 뒷 부분의 전부입니다. 그렇다면 Damping Factor는 무엇일까요? 구글 논문에서는 이를 '페이지를 이동할 확률'이라고 표현합니다. 즉 사용자가 검색을 통해 해당 페이지에 접근했고 다른 페이지로 이동하지 않고 머문다면 d = 0이되고 (1-d)이 1로 A페에지의 페이지랭크 값은 1이 됩니다. 즉, 해당 페이지로 들어오면 다른 페이지로 이동하지 않는다는 것이죠. 그런데 그런 페이지가 있을까요..? 없습니다. 논문에서도 d의 값을 0.85로 다른 페이지에 이동할 확률을 85%로 설명하고 있습니다. 여기까지 오셨으면 페이지랭크에 대한 내용을 다 이해하신 겁니다.

그런데 이런 훌륭한 알고리즘에도 단점이 존재하니 우리나라의 퍼가기가 유행한 것에 매우매우 둔감한 것입니다. 즉 퍼가기를 통한 웹 사이트의 확장은 해당 알고리즘으로 원문에 대해 적용하지 못하기 때문에 퍼가기가 난무한다면 알고리즘이 힘을 많이 잃게 된는 것이죠.
2) 텍스트랭크(TextRank)
텍스트랭크를 탄생시켜준 페이지랭크에 대해서 알아봤으니 이제 텍스트랭크에 대해서 알아보겠습니다. 페이지랭크에서는 웹사이트에 존재하는 많은 페이지간 사이트들 간의 관계에 중점을 두었습니다. 텍스트 랭크는 문서 하나를 하나의 웹 세상으로 보는 것입니다. 그렇게 된다면 문서를 구성하는 문장들이 존재하는데 이 문장들이 하나의 웹사이트가 되는것이죠. 그러면 각 문장들간의 관계가 존재할 것입니다. 이를 통해 문서에서 문장들의 점수가 할당이 될 것이고 이를 나열하여 문서를 대표할 수 있는 문장들을 추출해내는 것이죠. 이게 문서 요약 방법 중 하나인 추출적 요약(extractive summarization)에 해당합니다. 문서를 문장 단위로 분리하고 이를 전처리 작업을 진행하여 문장을 하나의 임베딩 벡터로 만듭니다. 여기서 임베딩 벡터로 만드는 방법은 사용자가 다양하게 결정할 수 있습니다. 훈련된 임베딩 정보를 가져와 적용할 수 있고 직접 임베딩을 처음부터 구현할 수 있습니다. 데이터셋에 맞는 훈련된 임베딩이 있다면 불러와 사용하는게 자원적으로 가장 좋은 방법입니다. 이후 문장의 임베딩 벡터들을 활용해 그래프(Martix)를 만들어내고 TextRank를 적용하면 문서의 요약 문장을 만들어 낼 수 있습니다. 글로 설명하면 어려울 수 있으니 프로세스는 아래 그림을 참고하시면 됩니다.
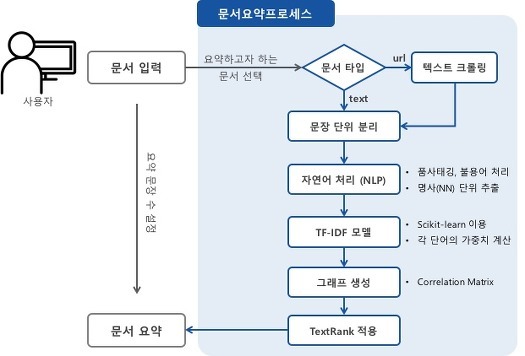
참고 레퍼런스
PageRank - https://sungmooncho.com/2012/08/26/pagerank/
'머신러닝&딥러닝 > NLP' 카테고리의 다른 글
| NLP - RoBERTa(Robustly optimized BERT approach) 논문 톺아보기 (0) | 2023.10.17 |
|---|---|
| NLP - 텍스트 요약(Text Summarization) + BERTsum 논문 톺아보기 (1) | 2023.10.16 |
| 모바일 4가지 게임 리뷰 토픽 모델링 분석(6) (0) | 2023.10.12 |
| 모바일 4가지 게임 리뷰 토픽 모델링 분석(5) (2) | 2023.10.12 |
| 모바일 4가지 게임 리뷰 토픽 모델링 분석(4) (1) | 2023.10.12 |



