
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- NLP
- 데이터리안
- 문맥을 반영한 토픽모델링
- geocoding
- 데이터넥스트레벨챌린지
- SBERT
- 토픽 모델링
- Optimizer
- 붕괴 스타레일
- 코사인 유사도
- 조축회
- 포아송분포
- 트위치
- BERTopic
- 블루 아카이브
- Tableu
- 클래스 분류
- KeyBert
- 개체명 인식
- 데벨챌
- 다항분포
- 구글 스토어 리뷰
- 블루아카이브 토픽모델링
- 자연어 모델
- 원신
- 옵티마이저
- 피파온라인 API
- CTM
- LDA
- Roberta
- Today
- Total
분석하고싶은코코
NLP - RoBERTa(Robustly optimized BERT approach) 논문 톺아보기 본문
이번 포스팅에서는 BERT 모델에서 파생되어 좋은 성능을 보이고 많은 자연어처리 분야에서 사용되고 있는 모델의 기반인 RoBERTa 논문을 살펴보는 포스팅을 진행해보겠습니다. (영어 실력이 좋은 편은 아니라 오역이 있을 수 있으니 알려주시면 감사하겠습니다!)
Abstract
RoBERTa의 탄생은 BERT가 undertrained(과소훈련)되어 있고 이후 출시한 모들의 성능이 비슷한 수준이라는 점을 발견하였기 때문이라고 합니다. 모델에서 사용하는 하이퍼파라미터 변경은 결과가 크게 변함을 언급하고 있고, GLUE, RACE, SQuAD에서 최고의 성능을 보여주었다고 합니다.

Introduction
RoBERTa가 등장한 배경에 대해서 설명합니다. Abstract에서 이야기했듯 BERT가 undertrained된 것을 발견하고 이를 향상시키기 위해 기존 버트와 다른 4개의 다른점을 소개하고 있습니다. 그 내용이 담긴 소개문의 일부를 발췌하였습니다.
- 더 많은 데이터로, 더 큰 배치 사이즈를 통해 오래 훈련됐다
- NSP(Next Sentence Predcition)과정을 삭제
- 더 긴 시퀀스에 대한 훈련
- MLM을 Dynamically MLM로 변경

Background
이 섹션에서는 BERT에 대해서 이해하는 내용에 대해서 기술되어 있습니다. BERT가 어떻게 훈련되어가는지에 대한 내용이라 이 페이지에서는 추가적으로 작성하지는 않겠습니다. 블로그에 포스팅된 BERT이해하기 포스팅을 참고해주세요.
Experimental Setup
- Implementation
RoBERTa가 탄생하는 과정의 설정들에 대한 설명입니다. 기존 BERT에서 어떻게 변경된 점들이 있는지에 대한 설명입니다.
기본적으로 학습률이나 준비과정으 제외한 optimizer와 hyperparameters는 기본 BERT에서 그대로 가져왔다고 합니다. 옵티마이저의 Adam의 엡실론과 β에 대해서 언급하는데 엡실론 값이 굉장히 민감하였는데 때로는 보다 좋은 안정적인 결과를 보여주기도 했다고 합니다. 또한, 큰 배치 사이즈를 훈련시키기 위해 β_2값이 0.98일때 안정적이였다고 합니다.
훈련 과정에서 짧은 시퀀스에 대해서는 랜덤하게 훈련시키지 않았고, 첫 업데이트에서 90%는 문장을 축약하지 않고 그대로 훈련했다고 합니다.
- Data
BERT 모델은 훈련 시키는 데이터가 많을 수록 성능이 좋아짐을 언급하며 160GB의 텍스트 데이터를 훈련시켰다고 언급하고 있습니다. 이에 훈련된 데이터는 다음과 같습니다.BOOKCORPUS (Zhu et al., 2015) plus English WIKIPEDIA.
- Book Corpus (16GB)
- CC-news (76GB)
- OPENWEBTEXT (38GB)
- Stories (31GB)
- Evaluation
DownStream은 소개문에서 이야기한 좋은 성능을 보여주었던 GLUE, RACE, SQuAD를 통해 진행하였다고 합니다. 해당 데이터에 대한 설명을 하고 있어 따로 언급하지는 않겠습니다.
Training Procedure Analysis
훈련에 앞서 기본 BERT의 하이퍼파라미터를 그대로 사용했다고 합니다. 이전에 BERT포시틍에서 작성한 d_model, head_nums, layer_nums값을 말합니다.
Static vs. Dynamic Masking
이 부분이 기존 BERT와 가장 큰 다른점이라 볼드처리하였습니다. NSP과정이 사라지고 MLM과정이 발전한 부분입니다.
기존의 BERT는 훈련을 위해 [MASK] 토큰을 랜덤하게 배정하고 이를 바탕으로 훈련을 진행합니다. 그런데 이 과정중에 문제가 epoch마다 동일한 마스킹 데이터가 훈련되는데 이 과정에 과적합이 발생하는 위험이 있고 BERT에 대한 문제점으로 꼽기도 합니다. 실제로 BERT에서는 이 문제를 피하기 위해서 마스킹할 데이터에서도 또 분리해서 데이터를 나누는 작업을 진행했습니다. 그런데 RoBERTa에서는 해당 마스킹 방법을 사용하지 않고 모델에 데이터가 들어갈때 매번 새로운 마스킹 작업을 진행하는 방법을 사용하여 BERT의 단점을 보완하고자 하였습니다. 아래 사진은 기존 BERT모델과 마스킹 성능에 대한 비교입니다. 동적 마스킹이 조금 우세함을 확인하였기에 사용하였다고 합니다.
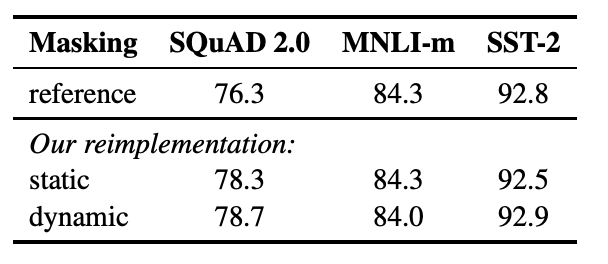
아래 RoBERTa github에 있는 마스킹 토큰을 구현하기 위한 클래스 설명 부분입니다.
class MaskTokensDataset(BaseWrapperDataset):
"""
A wrapper Dataset for masked language modeling.
Input items are masked according to the specified masking probability.
Args:
dataset: Dataset to wrap.
sizes: Sentence lengths
vocab: Dictionary with the vocabulary and special tokens.
pad_idx: Id of pad token in vocab
mask_idx: Id of mask token in vocab
return_masked_tokens: controls whether to return the non-masked tokens
(the default) or to return a tensor with the original masked token
IDs (and *pad_idx* elsewhere). The latter is useful as targets for
masked LM training.
seed: Seed for random number generator for reproducibility.
mask_prob: probability of replacing a token with *mask_idx*.
leave_unmasked_prob: probability that a masked token is unmasked.
random_token_prob: probability of replacing a masked token with a
random token from the vocabulary.
freq_weighted_replacement: sample random replacement words based on
word frequencies in the vocab.
mask_whole_words: only mask whole words. This should be a byte mask
over vocab indices, indicating whether it is the beginning of a
word. We will extend any mask to encompass the whole word.
bpe: BPE to use for whole-word masking.
mask_multiple_length : repeat each mask index multiple times. Default
value is 1.
mask_stdev : standard deviation of masks distribution in case of
multiple masking. Default value is 0.
"""
Model Input Format and Next Sentence Prediction
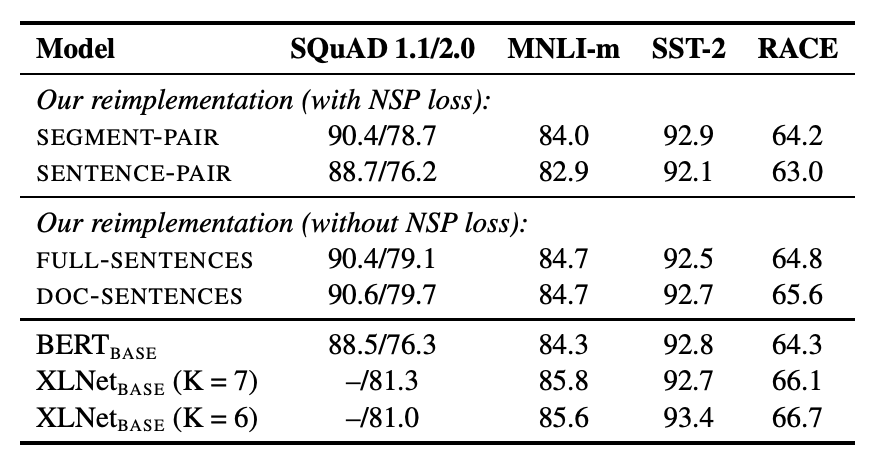
RoBERTa의 다른점이라면 MLM 방식의 변경과 NSP를 삭제한 점입니다. 실제로 NSP작업을 제거하면 BERT의 성능 하락을 확인한 논문에 대해서 언급하며 NSP loss의 중요성을 강조하지만, NSP loss의 필요성에 대한 의문점들이 지속적으로 제시되고 있다고 설명하고있습니다. (데이터와 해당 결과에 대한 세팅은 논문을 참고해주세요. ) NSP loss 삭제에 대한 근거로는 BERT의 downstream과정에서는 개별 문장을 통해서 진행하게 되면 성능이 하락하는 현상을 발견하였는데 이에 대한 해결방법으로 NSP loss를 제거하고 진행하였을때 비슷하거나 조금 더 좋은 성능을 보여주는 것을 발견했기 때문이라고 합니다. NSP loss 제거를 위한 Full-sentence 와 Doc-sentecne의 차이는 문서를 이어서 데이터로 만드는(Full)것의 차이입니다. Doc은 문서가 끝났을때 데이터가 없더라도 다음 문서에서 문장을 가져와 데이터를 형성하지 않습니다.
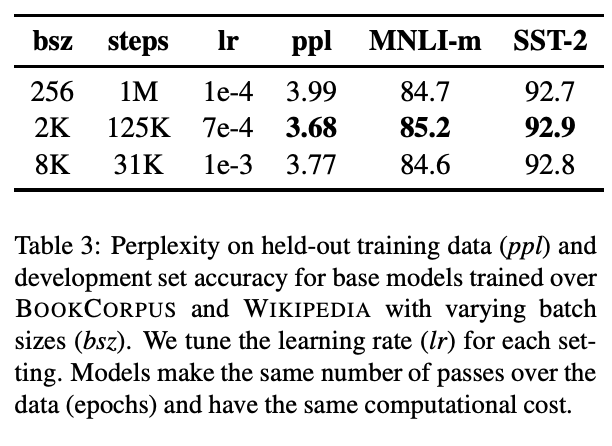
Training with large batches
머신러닝, 딥러닝 모델에서는 배치사이즈(batch_size)와 steps가 결정되는데 RoBERTa에서는 batch사이즈가 커짐에 따라 속도와 성능향상에 도움이 된다는 과거의 신경망 기계 번역의 내용을 언급하며 배치 크기를 늘리고 step을 줄여 BERT와 성능 비교를 위한 동일성을 확보했음을 이야기합니다.
Text Encoding
RoBERTa의 텍스트 인코딩 과정은 BERT와 조금은 다른 과정을 거칩니다. BERT와 같은 BPE알고리즘을 사용하였지만 그 과정에 조금 다릅니다. 기존의 BPE는 유니코드를 사용한 과정을 진행하는데 bytes를 이용한 BPE를 소개하며 BERT와 다르게 진행한 부분에 대해서 설명하고 있습니다. BERT의 토크나이저는 일부 전처리 과정을 거쳐 토크나이저를 형성하고 있지만 RoBERTa의 토크나이저는 전처리 과정이 없지만 더 많은 데이터 셋의 바이트 BPE를 사용하고 전처리 과정을 거치지 않은 토크나이저를 형성하였다고 합니다. 이 부분은 논문에서도 성능이 좋을것이라 기대하고 채택하였다고 작성되어 있습니다. bytes BPE에 대해서는 GPT2논문에서 소개된 내용이므로 궁금하신 분은 링크를 클릭하여 직접 읽어보시길 추천드립니다.
이후에는 모델의 성능의 결과를 이야기하는 부분이니 직접 논문에 들어가서 확인해보시길 바랍니다.
Conclusion
앞서 이야기 됐던 주요 변경점들과 그로 인한 BERT와 비교해 좋은 성능에 대해 다시금 이야기하고 있습니다

이번 포스팅에서는 논문을 살펴보는 것으로 마무리하고 다음 포스팅에서 RoBERTa 모델을 가져와 직접 데이터를 적용해보도록 하겠습니다.
'머신러닝&딥러닝 > NLP' 카테고리의 다른 글
| NLP - Pytorch Finetune LightningModule (1) | 2023.10.24 |
|---|---|
| NLP - STS, NLI Downstream 구현(SBERT) (1) | 2023.10.23 |
| NLP - 텍스트 요약(Text Summarization) + BERTsum 논문 톺아보기 (1) | 2023.10.16 |
| NLP - 텍스트랭크(TextRank) (1) | 2023.10.16 |
| 모바일 4가지 게임 리뷰 토픽 모델링 분석(6) (0) | 2023.10.12 |


