
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Tableu
- SBERT
- 옵티마이저
- 원신
- 다항분포
- 개체명 인식
- 구글 스토어 리뷰
- 자연어 모델
- 블루아카이브 토픽모델링
- KeyBert
- 조축회
- 포아송분포
- 문맥을 반영한 토픽모델링
- geocoding
- BERTopic
- Optimizer
- 데이터리안
- 트위치
- 데이터넥스트레벨챌린지
- 피파온라인 API
- 붕괴 스타레일
- 토픽 모델링
- 블루 아카이브
- Roberta
- LDA
- NLP
- 데벨챌
- CTM
- 클래스 분류
- 코사인 유사도
- Today
- Total
분석하고싶은코코
NLP - STS, NLI Downstream 구현(SBERT) 본문
이번 포스팅에서는 STS, NLI라는 downstream작업을 직접 구현해봅니다. 한국어의 모델 성능을 평가에 사용하는 대표적인 데이터셋은 카카오 브레인에서 공개한 KorSTS/KorNLU와 KLUE 프로젝트에서 공개한 KLUE 벤치마크셋 2가지입니다. 이번 포스팅에서는 카카오 브레인에서 제공한 데이터를 사용할 계획입니다.
SBERT 논문에서 STS를 구현한 방법은 두 가지입니다. 순수하게 STS데이터 만을 사용해서 유사도를 구한 방법과 NLI데이터로 사전훈련을 시키고 이후에 STS를 추가학습 시킨 continue learning 방법입니다. 이를 하나씩 구현해보겠습니다.
데이터셋 확인
학습 방법을 구현하기 앞서 KLUE에서 제공해주는 STS, NLI 데이터가 어떻게 생겼는지 확인해보겠습니다.
STS(Semantic Textual Similarity)
STS는 두 문장쌍으로 데이터가 구성되어 있고 두 문장 사이의 유사도를 측정하는 방법입니다. KorSTS에서 제공하는 데이터셋은 기계 번역을 통한 데이터(train)과 번역후 사람이 검증한 문장 데이터(dev, test)가 존재합니다. STS에 대한 평가 기준은 Spearman상관입니다.

NLI(Natural Language Inference)
NLI 데이터 역시 두 개의 문장 쌍이 제공되는데 두 문장이 서로 수반(entailment), 모순(contradiction), 중립(neutral)인지를 라벨 값으로 갖습니다. NLI데이터 역시 기계번역을 통한 데이터와 번역후 사람이 검증한 데이터가 존재합니다. 평가 기준은 Acuarrcy입니다.

# 예시로 깃헙에서 STS_train파일만 받아와 출력해보는 예제입니다.
# 카카오브레인 깃헙에서 직접 다운로드하여 모든 STS, NLI파일을 로드 하시면됩니다.
# STS-train가져오는방법
import urllib
urllib.request.urlretrieve("https://raw.githubusercontent.com/kakaobrain/kor-nlu-datasets/master/KorSTS/sts-train.tsv", filename="KorSTS_train.tsv")
cols = ['genre', 'filename', 'year', 'id', "score", 'sentence1', 'sentence2']
sts_train = pd.read_csv('./KorSTS_train.tsv', sep='\t', names = cols, skiprows=1)
STS단독 훈련
STS훈련 방법은 다음과 같습니다. 지난번 SBERT에 대한 설명을 할때 연속적 데이터에를 다룰때 언급한 부분입니다. 이 과정을 통해 두 문장의 유사성을 파악하게 됩니다. 이 과정을 그대로 구현해보도록 하겠습니다.

우선 데이터를 모두 불러왔다는 가정하에 진행이 됩니다. 모델이 학습할 수 있는 형태의 데이터 형태로 만들어줍니다. 형태는
(texts= [sentence1, sentence2], label=score)의 형태로 맞춰주면 됩니다. 이후에 훈련데이터는 배치사이즈로 묶고 검증과 테스트기를 embeddingsimilarityevaluator를 사용하여 만들었습니다.
입력 데이터만들기
from sentence_transformers.readers import InputExample
from torch.utils.data import DataLoader
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
def make_sts_input_example(dataset):
input_examples = []
for i, data in dataset.iterrows():
sentence1 = data['sentence1']
sentence2 = data['sentence2']
# 저는 데이터를 읽어올때 제대로 읽어오지 못해서 예외작업을 진행했습니다. 데이터를잘 불러왔다면 해당 부분은 주석처리해주세요.
if pd.isna(sentence2):
try:
sentence1, sentence2 = sentence1.split('\t')
except:
sentence1, sentence2 = data['sentence1'].split('\n')[0].split('\t')
_,_,_,_, tmp_score, tmp_s1, temp_2 = data['sentence1'].split('\n')[1].split('\t')
tmp_score = float(tmp_score) / 5.0
input_examples.append(InputExample(texts=[tmp_s1, temp_2], label=tmp_score))
pass
score = (data['score']) / 5.0 # normalize 0 to 5
input_examples.append(InputExample(texts=[sentence1, sentence2], label=score))
return input_examples
# Make_input_form
sts_train_examples = make_sts_input_example(sts_train)
sts_val_examples = make_sts_input_example(sts_val)
sts_test_examples = make_sts_input_example(sts_test)
# Train Dataloader
train_dataloader = DataLoader(
sts_train_examples,
shuffle=True,
batch_size=16,
)
# Evaluator by sts-validation
dev_evaluator = EmbeddingSimilarityEvaluator.from_input_examples(
sts_val_examples,
name="sts-dev",
)
# Evaluator by sts-test
test_evaluator = EmbeddingSimilarityEvaluator.from_input_examples(
sts_test_examples,
name="sts-test",
)
논문에서는 Korean RoBERTa와 XML-R 두 가지 모델을 통해 실험을 진행했습니다. 저는 Korean RoBERTa에 대해서만 진행해보겠습니다. XML-R에 대해서 궁금하신 분들은 파라미터를 변경하여 진행해보시면 될 것 같습니다.
모델 + 풀링
from sentence_transformers import SentenceTransformer, models
PRE_TRAINED_MODEL1 = 'klue/roberta-small'
PRE_TRAINED_MODEL2 ='xlm-roberta-base'
embedding_model = models.Transformer(
model_name_or_path=PRE_TRAINED_MODEL1,
max_seq_length=256,
do_lower_case=True
)
pooling_model = models.Pooling(
embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,
)
model = SentenceTransformer(modules=[embedding_model, pooling_model])
훈련
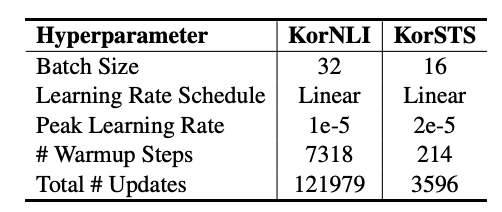
논문에서는 STS데이터에 대한 파라미터들은 다음과 같았습니다. 추가적으로 언급되지 않은 부분은 epoch은 10회 진행하였습니다. 저는 여기서 다르게 진행할 부분은 warm-up-steps를 214가 아닌 데이터의 10%로 설정하였습니다. 또한 loos fun의 경우 CosineSimilarityLoss로 설정하였습니다.
from sentence_transformers import losses
from datetime import datetime
import math
# config
sts_num_epochs = 10
train_batch_size = 16
sts_model_save_path = 'output/training_sts-'+PRE_TRAINED_MODEL1.replace("/", "-")
# loss
train_loss = losses.CosineSimilarityLoss(model=model)
# warmup steps
warmup_steps = math.ceil(len(sts_train_examples) * sts_num_epochs / train_batch_size * 0.1)
# Training
model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=dev_evaluator,
epochs=sts_num_epochs,
evaluation_steps=int(len(train_dataloader)*0.1),
warmup_steps=warmup_steps,
learning_rate=sts_lr,
output_path=sts_model_save_path
)
결과를 확인해보면 근사한 값을 얻은것을 확인할 수 있습니다. 저는 Korean RoBERTa의 small 모델을 불러왔기 떄문에 base에 비해 조금 낮은 결과를 얻은 것 같습니다. 그래도 small을 통해서도 base와 비슷한 수준의 결과를 확인할 수 있었습니다.
결과
test_evaluator(model, output_path=sts_model_save_path)
#결과
0.8290353649145727
NLI + STS continue learning
STS훈련에 앞서 NLI에 대한 훈련을 진행해준다는것을 제외하면 크게 다른게 없습니다. 이번에는 데이터를 불러오는 과정은 생략했습니다. github에 있는 데이터를 불러와서 그대로 사용해주시면됩니다. 중복된 문장이 있고 그에 해당 하는 데이터들이 있어서 사전으로 만들고 이를 무작위로 만들어 데이터 셋을 만들었습니다. 말로 이해하기가 어렵다면 직접 중복되는 데이터를 확인해보시면 왜 아래처럼 입력 데이터를 구성했는지 이해하실 수 있습니다.
입력 데이터 만들기
import random
def make_nli_triplet_input_example(dataset):
train_data = {}
def add_to_samples(sent1, sent2, label):
if sent1 not in train_data:
train_data[sent1] = {'contradiction': set(), 'entailment': set(), 'neutral': set()}
train_data[sent1][label].add(sent2)
cnt=0
for i, data in dataset.iterrows():
sent1 = data['sentence1'].strip()
sent2 = data['sentence2'].strip()
label = data['gold_label']
# 저는 데이터를 불러올때 형태를 제대로 불러오지 못해서 잘못 불러온 데이터는 넘겼습니다. 228개의 데이터를 사용하지 않았습니다.
if ('\t' in sent1 or '\t' in sent2):
cnt+=1
continue
add_to_samples(sent1, sent2, label)
add_to_samples(sent2, sent1, label) #Also add the opposite
# print('PASSING DATA : ',cnt)
input_examples = []
for sent1, others in train_data.items():
if len(others['entailment']) > 0 and len(others['contradiction']) > 0:
input_examples.append(InputExample(texts=[sent1, random.choice(list(others['entailment'])), random.choice(list(others['contradiction']))]))
input_examples.append(InputExample(texts=[random.choice(list(others['entailment'])), sent1, random.choice(list(others['contradiction']))]))
return input_examples
# make Input
nli_train_data = make_nli_triplet_input_example(nli_train)
모델 + 풀링
NLI를 통해서는 모델의 첫번째 훈련만 진행할 계획이기 때문에 train data만 사용합니다.
# Train Dataloader
train_dataloader = DataLoader(
nli_train_data,
shuffle=True,
batch_size=32,
)
embedding_model = models.Transformer(
model_name_or_path=PRE_TRAINED_MODEL1,
max_seq_length=256,
do_lower_case=True
)
pooling_model = models.Pooling(
embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,
)
model = SentenceTransformer(modules=[embedding_model, pooling_model])훈련(NLI)
STS훈련때와 다른건 다음과 같습니다.
- loss fun을 MultipleNegativeRankingloss를 사용
- 배치 사이즈는 논문에서 기록된 32
- 원래 10번의 에포크를 실행했지만 시간상 저는 1번만 진행
from sentence_transformers import losses
nli_num_epochs = 1
train_batch_size = 32
nli_model_save_path = 'output/training_nli_by_MNRloss_'+PRE_TRAINED_MODEL1.replace("/", "-")
train_loss = losses.MultipleNegativesRankingLoss(model)
warmup_steps = math.ceil(len(nli_train_data) * nli_num_epochs / train_batch_size * 0.1)
model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=dev_evaluator,
epochs=nli_num_epochs,
evaluation_steps=int(len(train_dataloader)*0.1),
warmup_steps=warmup_steps,
output_path=nli_model_save_path,
use_amp=False
)
훈련(STS)
이후에는 저장된 모델을 불러와 STS를 이어서 훈련을 진행해주면 됩니다. 이번에는 10->5로 절반으로 줄였습니다. colab에서 지원해주는 시간이 한정되어 있어서 길게 하지는 못했습니다. 혹시 직접해보시는 분들은 10회로 논문과 똑같이 해보시길 추천드립니다.
model = SentenceTransformer(nli_model_save_path)
sts_num_epochs = 5
train_batch_size = 16
sts_model_save_path = 'output/training_sts_continue_training-'+PRE_TRAINED_MODEL1.replace("/", "-")
train_loss = losses.CosineSimilarityLoss(model=model)
warmup_steps = math.ceil(len(sts_train_examples) * sts_num_epochs / train_batch_size * 0.1) #10% of train data for warm-up
model.fit(
train_objectives=[(train_dataloader, train_loss)],
evaluator=dev_evaluator,
epochs=sts_num_epochs,
evaluation_steps=int(len(train_dataloader)*0.1),
warmup_steps=warmup_steps,
output_path=sts_model_save_path
)
test_evaluator(model, output_path=sts_model_save_path)
# 결과
0.8570831481973878
결론
결과를 보면 85.7정도로 이전에 STS만으로 진행했던 것보다 훨씬 좋은 결과를 받았습니다. 심지어 NLI의 훈련은 1번을 진행했고 STS를 5번으로 축소하여 훈련을 진행했는데 보다 나은 결과를 받을 수 있었습니다. 실험을 한 번만 진행한 결과이므로 단정짓기는 어렵지만 NLI를 통해 모델을 훈련시키고 이어서 STS로 훈련을 시키는것이 모델의 성능을 향상시켜준다는 것을 확인해 볼 수 있었습니다.
논문 리뷰는 다음 포스팅으로...
많은 모델이 STS, NLI 성능 평가하는 downstream작업을 직접 진행해봤습니다. 사실 논문에 대한 리뷰를 먼저하고 직접 해보는 코드를
올려보려고 했는데 논문을 정독하는게 아니라 궁금한 부분만 먼저 읽어보고 구현해버려서 이 부분에 대한 포스팅을 먼저 진행했습니다. 리뷰 포스팅에서는 빼먹고 적용하지 못한 부분이 있는지 체크하면서 리뷰를 진행해보는걸로!!!
'머신러닝&딥러닝 > NLP' 카테고리의 다른 글
| 간단한 텍스트 생성(Text Generation) 모델 구현해보기 (0) | 2023.12.16 |
|---|---|
| NLP - Pytorch Finetune LightningModule (1) | 2023.10.24 |
| NLP - RoBERTa(Robustly optimized BERT approach) 논문 톺아보기 (0) | 2023.10.17 |
| NLP - 텍스트 요약(Text Summarization) + BERTsum 논문 톺아보기 (1) | 2023.10.16 |
| NLP - 텍스트랭크(TextRank) (1) | 2023.10.16 |

