
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 피파온라인 API
- Optimizer
- 자연어 모델
- 데벨챌
- 다항분포
- 블루아카이브 토픽모델링
- NLP
- 코사인 유사도
- 원신
- 구글 스토어 리뷰
- BERTopic
- 조축회
- KeyBert
- 데이터리안
- 포아송분포
- 트위치
- 토픽 모델링
- geocoding
- 클래스 분류
- 데이터넥스트레벨챌린지
- 개체명 인식
- 문맥을 반영한 토픽모델링
- Tableu
- CTM
- 붕괴 스타레일
- Roberta
- SBERT
- 옵티마이저
- LDA
- 블루 아카이브
- Today
- Total
분석하고싶은코코
기초 통계학 - 확률변수와 기댓값 본문
확률변수(Random variable)
확률변수란 표본공간에서 정의된 실함수이다. 이렇게 표현하면 이해하기 어려우니 쉽게 이야기하면 확률실험을 통해 만들어진 표본집단에서 특정확률로 발생하는 결과를 실수형태로 부여하는 값을 말한다. 예를들면 동전을 던지는 실험에서 앞면과 뒷면이 나올 확률은 각각 1/2인데 이에 대한 결과값은 결국 앞면과 뒷면이다. 이래도 잘 이해가 안될 수 있는데 자세한 예를 들어보면 동전을 총 3번 던지는 실험을 진행한다. 그러면 표본공간은 다음과 같다.
{ 앞앞앞, 앞앞뒤, 앞뒤뒤, 앞뒤앞, 뒤앞앞, 뒤뒤앞, 뒤앞뒤, 뒤뒤뒤 }
이때 사건을 '앞면
이 나온 수'라고 할때 위 표본공간은
{ 3, 2, 1, 0 }이 된다. 이 숫자들이 확률변수가 된다.
이를 X라 하면 그 안에있는 하나하나를 소문자 x로 표현하고 숫자로 라벨링이 가능하다.
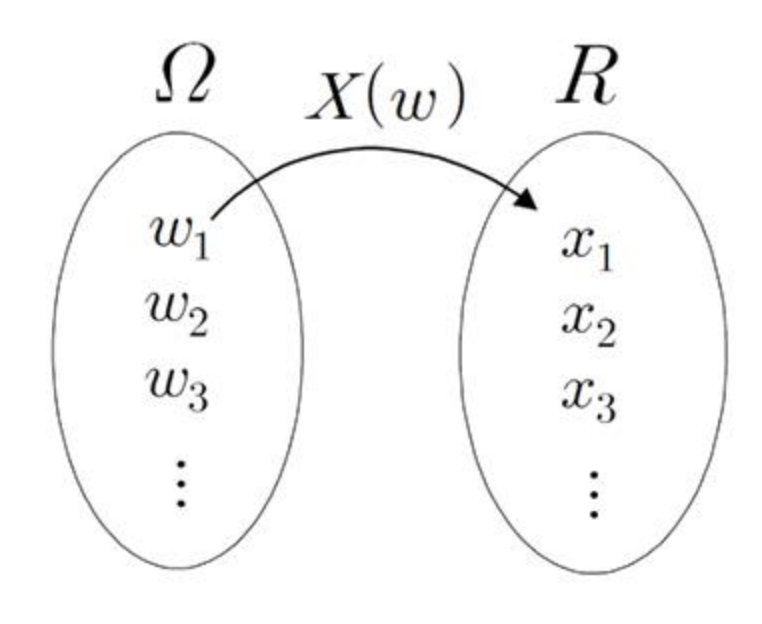
이러한 확률변수에는 크게 대표적인 두 가지가 있는데 이산확률 변수와 연속확률 변수 두 가지가 있습니다. 확률 변수를 통해 나오는 값이 있는데 이를 확률이라고 이러한 확률들이 위치와 퍼짐정도를 표현하는 분포가 존재하는데 두 가지가 다른 형식으로 표현이 됩니다. 이는 뒤쪽에서 좀 더 살펴보기로 하고 공통적으로 이 분포에 대해서 확률 분포라는 용어를 사용합니다.
확률분포(Probability Distribution)
확률 분포는 앞서 이야기한 확률 변수를 통해 대응되는 값을 표현하는 것입니다. 그런데 여기서 중요한 것은 앞서 이야기한 확률변수와 확률분포의 확률의 영어 표기가 다른점에 주목해야합니다. 확률변수의 확률은 무작위를 뜻하고 확률분포의 확률은 우리가 알고 있는 전체중 특정 사건이 일어날 확률을 뜻합니다. 즉 확률변수는 무작위로 발생하고 이렇게 발생한 것이 어느정도로 일어날 수 있는가에 대해서 표현하는 것이라 보면됩니다. 말이 복잡하니 위에서 든 예시인 동전 뒤집기를 예로들면
사건은 앞면이 나오는 경우였습니다.
{ 앞앞앞, 앞앞뒤, 앞뒤뒤, 앞뒤앞, 뒤앞앞, 뒤뒤앞, 뒤앞뒤, 뒤뒤뒤 } -> { 3, 2, 1, 0 }
확률변수 {3,2,1,0}인데 이는 제한된 사건안에서 무작위로 등장할 수 있는 값들입니다. 이에 대응되는 값들을 카운트해보면
{3 -> 1, 2 -> 3 , 1 -> 3, 0 -> 1}
이렇게 확률변수에 대응되는 값들이 나오는데 이를 경우의 수에서 등장한 사건횟수/전체횟수의 확률로 표시하면 { 1/8, 3/8, 3/8, 1/8} 이렇게되는데 이를 확률 분포라 하게된다. 즉, 동전을 던진다는 모집단에서 각각의 확률변수를 통해 대응되는 값들이 나왔고 이를 숫자적으로 표현하게 되는데 이게 바로 확률분포가 된다. 이런 확률분포를 표로 표시하는 것을 확률분포표라고 하게된다.

앞서 확률변수에서 이산형과 연속형 확률변수가 존재한다고 하였는데 이 확률분포를 표현하는 함수가 다른데 각각 '확률질량함수', '확률밀도함수'라 한다.
이산확률변수 : 확률질량함수
연속확률변수 : 확률밀도함수
확률질량함수(Probability mass function)
확률질량함수는 확률변수가 카운팅이 가능한 경우의 확률분포를 표현할떄 사용되는데 대표적인것이 앞서 이야기한 동전뒤집기가 해당된다. 확률질량함수는 다음과 같은 기본식으로 표현이 가능하다.

이 확률함수에 대한 성질은 3가지가 있는데
1. 0<= f(x) <= 1
2. 모든 확률의 합은 1
3. 확률변수 a와 b사이의 확률은 f(a)에서 f(b)까지의 합과 같다
3번의 성질로 인해서 누적분포함수라는 것이 존재하게 되는데 a가 없이 b자리에 특정 x의 값이 들어왔을때 다음과 같이 표현할 수 있다.
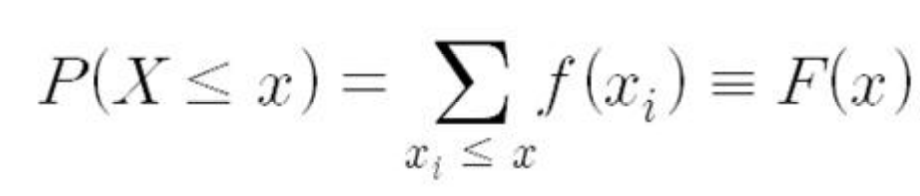
확률변수의 변환
확률변수의 변환의 경우 확률변수를 다른 형태로 변형하고 이에 대한 확률분포를 알아보는 것이다. 말로 설명하면 이해하기 어렵기에 예를들어보면 다음과 같은 확률변수가 있고

이를 제곱한 형태로 변환한 확률변수 w가 있다면 다음과 같다.

이제 w에 대한 확률 분포를 구한다고 한다면 기존에 x는 값이 4개였지만 w값이 겹치는 1이 존재하게 된다. 따라서 확률변수는 3개가 되고 그에 대한 확률은
w = 0일때 x의 값은 0하나에 대응되기에 0.3
w = 1일때 x의 값은 -1,1 두개에 대응되기에 0.1 + 0.2 = 0.3
w = 4일때 x의 값은 2하나에 대응되므로 0.4
이렇게 확률분포를 만들어 낼 수 있다.
확률밀도함수(Probability density function)
확률밀도함수는 히스토그램으로 이해하면 쉽게 이해할 수 있다. 히스토그램은 정해진 영역에 값들이 어느정도로 밀도인지 표현하는 그래프이다. 모집단에서 표본을 추출해 표현을 하게되면 히스토그램형태로 나오게 되는데 이를 무수히 많이 표본을 추출하여 표현하면 곡선형태의 종모양으로 표현이 가능하게 되는데 이를 확률밀도함수라 한다. 확률밀도함수에서의 확률은 구간에서의 면적이라고 생각하면 된다. 그 식은 다음과 같다.
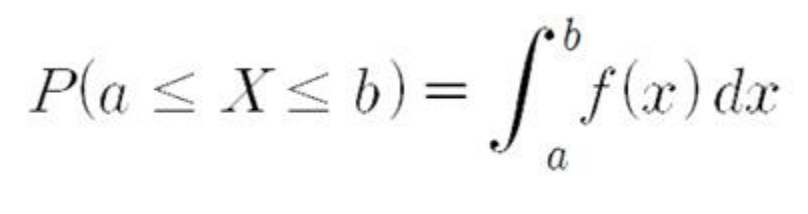
여기서 짚고 넘어가야할 부분이 있다. 확률밀도함수에서의 확률은 방금 이야기했듯 구간의 면적이 확률이 된다. 그래서 정확하게 특정지점을 짚어서 확률을 물어본다면 이때 확률은 0이된다. 그 이유는 확률밀도함수의 f(x)는 정확하게 이야기하면 확률이 아니라 그 구간에 어느정도로 밀집되어있는가를 나타내는 함수이기 때문이다. 따라서 확률밀도함수에서 P(a<= X <= b)는 P(a < X <b )와 같은 식이라 할 수 있다. 또한, 확률밀도함수에서의 누적분포함수는 다음과 같다.

확률변수의 기댓값
통계를 하지 않더라도 게임을 접하본 사람이라면 익숙한 단어인 '기댓값'이다. 이 기댓값이라는 단어는 쉽게 평균이라고 이야기할 수 있다. 그렇다면 그게 왜 기댓값인가에 대한 의문이 드는데 예를들어 1~6의 눈이 있는 주사위를 던진다고 생각해보자 내가 얻을 수 있는 주사위 눈의 기댓값은 계산해보면 3.5가 나온다. 이 3.5가 어떻게 나오는 것인가에 대해서 이야기해보자. 주사위를 5번 던져서 {1, 1, 2, 5, 6}이 나왔을때 평균은 3이다. 그럼 기댓값이랑 다르잖아!라고 할 수 있는데 기댓값을 구하는 방법은 정확하게 위에서 구한 평균을 구하는 공식은 같은데 조건이 무수히 많이 반복했다는 가정이 들어간다. 단순히 10번 100번이 아니라 무수히 많은 확률실험을 하게 됐을때 나오는 값의 평균을 기댓값이라 한다. 그래서 쉽게 평균이라 표현할 수 있는 것이다. 그런데 여기서 한 번 더 생각해볼 수 있는 부분은 표본 집단이 무수히 많아지면 우리는 이를 모집단이라 할 수 있게 된다 했다. 결국 기댓값이란 모집단의 평균이되고 이를 모평균이라 부르기도 한다는 점이다. 또한 이 모평균(기댓값)은 확률분포에서 무게중심으로 활용되기도 한다.
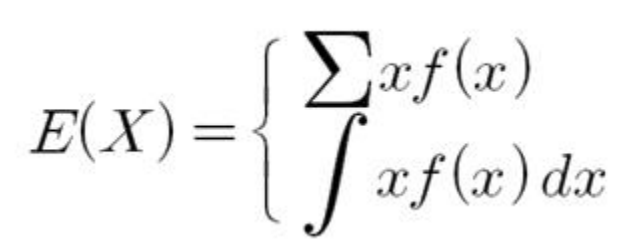
이산확률변수와 연속확률변수에서의 기댓값을 구하는 식은 다르지만 방식은 똑같다. 결국 해당 구간에서의 확률변수와 그 확률변수에 해당하는 값을 곱한 값들의 합이다. 확률변수가 연속하는 속성을 갖냐 갖지 않느냐에 따라서 쉽게 식으로 표현할 수 있고 적분을 이용해 계산할 수 있고로 나뉠 뿐이다.
'통계' 카테고리의 다른 글
| 기초 통계학 - 포아송, 기하, 음이항, 다항분포 (1) | 2023.09.22 |
|---|---|
| 기초 통계학 - 베르누이 실행, 이항 분포와 초기하 분포 (0) | 2023.09.21 |
| 기초 통계학 - 확률(2) (0) | 2023.09.19 |
| 기초 통계학 - 확률(1) (0) | 2023.09.19 |
| 기초 통계학(Basic Statistics) - 통계학과 모집단, 표본 (0) | 2023.09.18 |



